自动驾驶的认知重构:VLA 架构的工程真相
去年年底参加一个自动驾驶沙龙时,有个嘉宾说:“我们把 GPT-4o 接进座舱了,VLA 落地了。“台下还不少人点头。我当时就想,这哪是 VLA,这只是语音助手换了套皮肤。VLA 的真正价值根本不是让车跟你聊天,而是让车真的”看懂”路况并做出决策——把原来那一堆感知、预测、规划的模块,或者单一的端到端黑盒,变成一个能自己思考的系统。这半年多我们团队一直在折腾这条链路,才发现从”看懂”到”开起来”,中间全是坑。
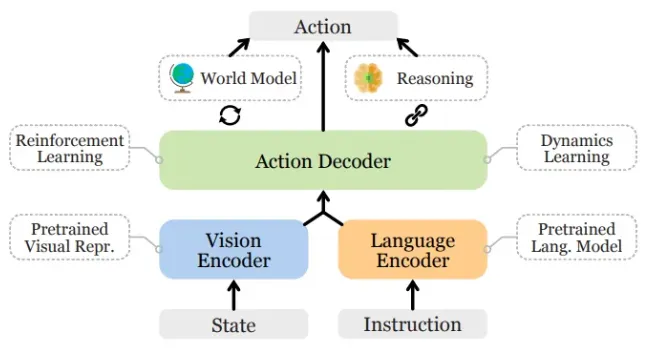
视觉编码:先解决”看不懂”的问题
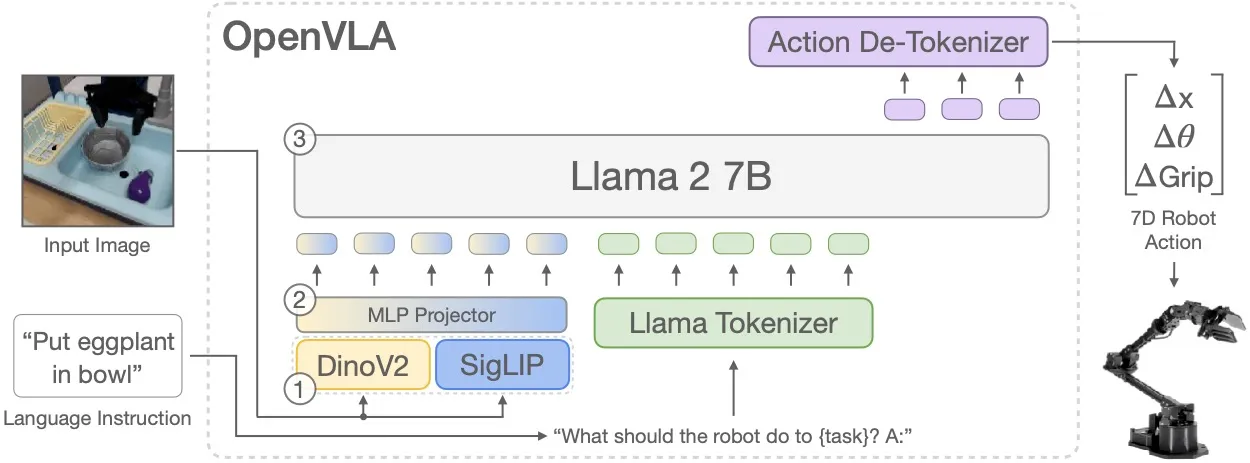
最开始的方案我们试过直接把 8 路摄像头的 RGB 流喂给 LLM。用 7B 参数的模型在 A100 上测了一下,推理延迟飙到 800ms——这还没算后处理。Attention 的计算量随输入长度平方增长,8 路 1080p 的图像,序列长度直接爆炸。而且模型根本学不明白,花了两周训练,连车道线都认不准,参数全浪费在重新学”什么是边缘”这种基础视觉任务上了。
后来不得不放弃这条路,引入 Vision Encoder 做特征压缩。我们试了 CLIP 和 SigLIP,最终选了 SigLIP,因为在夜间场景下它的特征稳定性比 CLIP 好大概 15%。编码器把图像切分成 16x16 的 Patches,每个 Patch 变成一个高维向量。这不像传统感知输出”这是车”、“那是人”的标签,而是保留纹理和空间信息。好处是遇到异形障碍物(比如倒下的树干),模型也能提取特征,不会因为训练数据里没出现过就漏检。
跨模态对齐:Projector 踩坑实录
特征提出来了,但 LLM 还是看不懂。视觉空间的向量跟文本 Embedding 完全是两套数学语言,得有个”翻译”。我们试过直接把特征向量 concat 到文本输入里,结果模型完全迷失——它根本不知道哪些数字是图像、哪些是指令。
后来加了 Projector,说白了就是个轻量 MLP,把视觉特征映射到 LLM 的词向量空间。训这个 Projector 花了我们整整一周,调了四五版网络结构。最开始用 3 层 MLP,发现小目标(比如锥桶)的特征会被压缩丢;改成 2 层加残差连接才好一些。现在这些”伪词向量”(Soft Tokens)虽然人类词表里找不到对应的单词,但 LLM 内部确实能把它跟”障碍物”、“行人”这些概念联系起来。不过说实话,这个映射是不是”无损”,我心里也没底,只是目前看效果还行。
推理与解释:CoT 的真实价值
这时候 LLM 终于能”看懂”画面了。跟传统端到端直接吐出轨迹点不同,VLA 会先”碎碎念”一段——这就是 CoT(思维链)。我们拿一段雨天晚高峰的测试录像试过:模型先输出”前方白色 SUV 刹车灯亮了,可能准备变道”,然后才给出轨迹。这种显式的中间步骤 Debug 起来方便多了。
上个月遇到个 Corner Case,路上有个倒下的交通锥,传统感知模型直接漏检,VLA 的 CoT 输出的是”地面有不明物体,形状不规则,建议减速”。虽然没认出是锥桶,但至少知道有风险——这就是基于常识的判断,而不是死记硬背训练数据里的标签。
从文本到动作:离散化的妥协
但 LLM 吐出来的是文本,底盘要的是扭矩和转角,这怎么接?我们不得不扩充词表,加了一堆控制 Token。这里有个权衡:连续量(比如坐标)怎么离散化。
试过分 100 个 bin,精度不够,规划出来的轨迹歪歪扭扭;试过 10000 个 bin,词表爆炸,推理变慢。最后折中选了 2000 个 bin,横向位置精度大概 5 厘米,够用。模型输出类似 <BIN_X_105> 这种标记,背后对应具体的坐标值。说实话,这个分箱粒度是拍脑袋定的——理论上应该有更优解,但我们暂时没资源做系统性的消融实验。
频率失配:LLM 与底盘的代沟
然后还有个麻烦:LLM 推理一次要 100ms(10Hz),但底盘控制需要 100Hz 的信号才能开得平顺。直接下发肯定抖成筛子。我们在封闭场地试过一次,车辆像抽搐一样,吓得测试员当场要求停车。
后来只能让 LLM 输出稀疏的轨迹点(Waypoints)作为”意图”,下游接 MPC 做插值和平滑。MPC 会根据车辆动力学模型,算出每一毫秒该给多少扭矩、打多少方向。这其实是两层控制:LLM 负责”想去哪”,MPC 负责”怎么去得稳”。
最后一道防线:别相信 AI
说实话,谁敢把命交给概率模型?我们在测试中就遇到过,LLM 在一个弯道处规划了一条贴边线,理论上能过,但旁边正好有辆货车占道——这种时候不能赌。
所以必须加一层 Safety Filter,纯规则、纯雷达,跟 AI 没关系。毫米波和超声波的数据实时跑碰撞检测,只要觉得有风险,直接掐掉 LLM 的指令,触发 AEB。这套逻辑我们写了几百条规则,覆盖各种 Cut-in、鬼探头场景。上个月 Safety Filter 误触发了一次,把正常变道给刹停了,原因是雷达把路边的灌木丛当成了障碍物。现在还在调阈值,是个体力活。但我宁愿它保守点,也别在关键时刻掉链子。
写在最后
这半年来最大的体会是:VLA 不是魔法,而是一堆工程妥协的叠加。每个环节都有权衡,每个参数都是拍脑袋或试出来的。那些发布会上说得天花乱坠的”端到端大模型”,背后其实都是这样的脏活累活。这篇文章只写到了 Safety Filter,实际上还有数据闭环、仿真验证、车端部署优化一大堆坑等着填。
迈向量产的深水区
虽然这套 VLA 架构已经跑通了全链路 Demo,但要实现真正的量产交付,前方还有几个”深水区”需要跨越。我们正在重点攻坚关键参数的消融实验,比如 Vision Encoder 的 Patch Size(8x8 vs 16x16)对小目标检测精度的具体影响。另外,目前的 2000 个控制 bin 是基于延迟和精度的最优平衡点,理论上 5000 个 bin 能提供更好的平滑度,但对推理延迟的压力需要在工程上进一步调优。
算力适配则是更硬核的挑战。目前的模型主要跑在 A100 集群上,而要部署到 Orin-X 甚至 Thor 等车规级芯片,Projector 层的算力消耗优化是必须跨越的门槛。车端部署的极致优化,将是下一阶段的硬仗。