
框出万物:2D目标检测的演进之路
2D目标检测,是计算机视觉领域最核心的任务之一。它的目标很简单:在一张图片中,同时回答两个问题——“是什么?“(分类)和”在哪里?“(定位)。
我从2016年开始接触目标检测,亲历了从Fast R-CNN到YOLO,再到DETR的完整变迁。这条路走下来,最大的感受是:每一次范式更替,本质上都是在”精度、速度、简洁性”这三者之间重新找平衡。
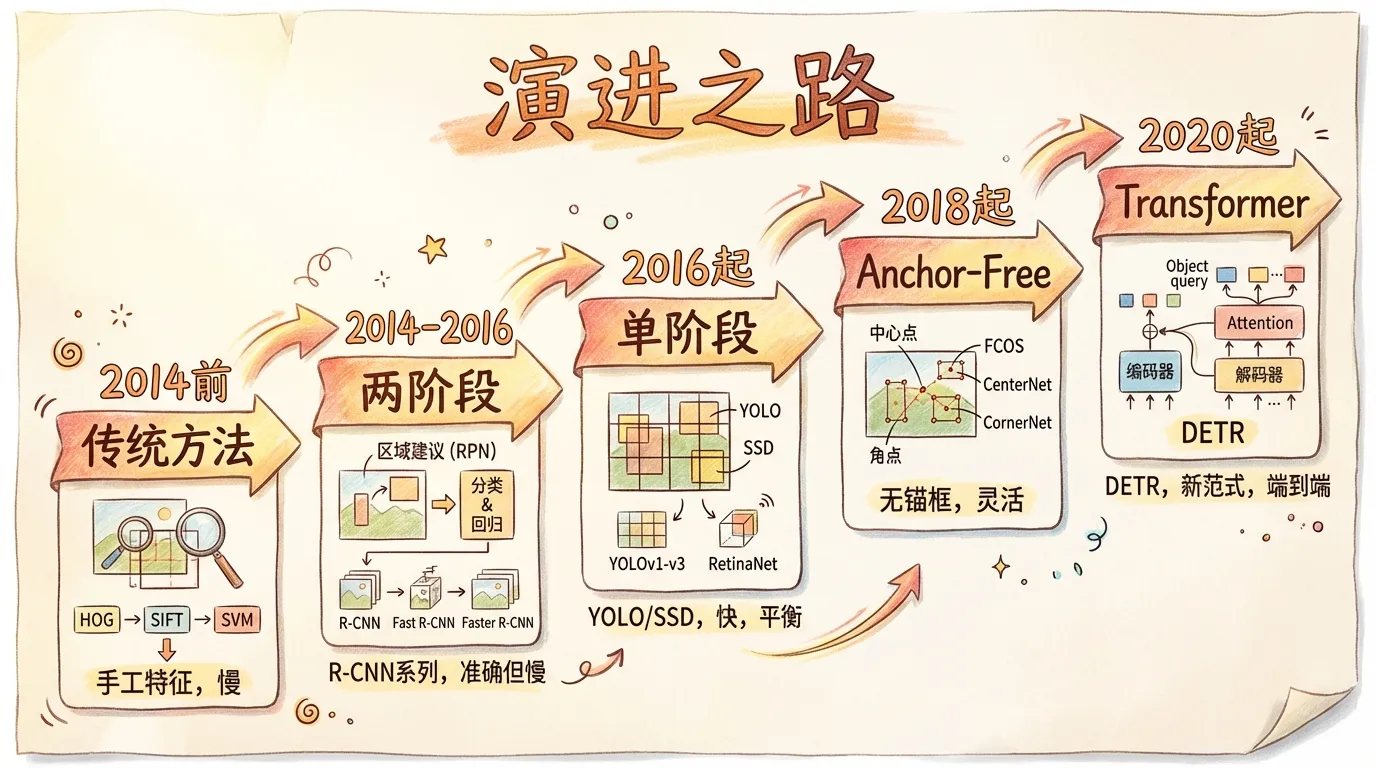
1. 蛮荒时代:传统方法 (2014年以前)
在深度学习一统江湖之前,目标检测是一个繁琐、多阶段的过程。
核心思想
滑动窗口(Sliding Window) + 手工特征(Hand-crafted Features) + 分类器(Classifier)。
流程拆解
-
区域选择:用一个固定大小的窗口,在图像上从左到右、从上到下地滑动。为了检测不同大小的物体,还需要缩放窗口或图像,重复滑动。这个过程会产生海量的候选区域。
-
特征提取:对于每一个候选区域,使用经典的特征描述子,如 HOG (Histogram of Oriented Gradients) 或 SIFT (Scale-Invariant Feature Transform),将其转换成一个固定长度的特征向量。
-
分类:将提取出的特征向量,喂给一个预先训练好的分类器,如 SVM (Support Vector Machine),来判断这个区域里是”目标”还是”背景”。
痛点
- 计算量巨大:滑动窗口策略毫无重点,会产生大量冗余的计算。我在早期实验中跑过一个HOG+SVM的Demo,检测一张800x600的图片要跑将近30秒,基本不可用。
- 特征表达力弱:手工设计的特征,对光照、形变、遮挡等情况的鲁棒性很差。稍微暗一点的光线,准确率就断崖式下跌。
2. 两阶段王朝:精度为王 (2014 - 2016)
2012年AlexNet的出现,标志着深度学习时代的到来。目标检测领域也迎来了革命。
核心思想
先找”可能”是物体的区域,再对这些区域进行精细分类和定位。这种”先粗后精”的思路,被称为**两阶段(Two-Stage)**方法。
代表模型:R-CNN 家族
R-CNN (2014)
-
区域提名(Region Proposal):用选择性搜索(Selective Search)算法,替代了蛮力的滑动窗口,生成约2000个高质量的候选框。
-
特征提取:将这2000个候选框,逐一缩放到固定尺寸,然后分别送入一个CNN(如AlexNet)中提取特征。
-
分类与回归:用SVM进行分类,再用一个线性回归器对边框位置进行微调。
-
问题:每个候选框都要独立过一遍CNN,计算冗余极大,速度极慢。我记得当时用GTX 980跑一张图要47秒,离实用还差得远。
Fast R-CNN (2015)
-
核心改进:只对整张图像进行一次CNN特征提取,得到一个特征图(Feature Map)。
-
将选择性搜索生成的候选框,投影(Project)到这个特征图上。
-
引入 RoI Pooling (Region of Interest Pooling) 层,从特征图上为每个不同大小的候选框提取出固定尺寸的特征向量。
-
结果:共享了卷积计算,速度大幅提升。但瓶颈转移到了CPU上运行的选择性搜索。
Faster R-CNN (2015)
-
终极形态:引入了RPN (Region Proposal Network),彻底抛弃了选择性搜索。
-
RPN是一个小型的全卷积网络,它直接在CNN的特征图上滑动,高效地生成高质量的候选框。
-
意义:首次将区域提名步骤也集成到了GPU中,实现了**端到端(End-to-End)**的训练。Faster R-CNN 成为了后续无数两阶段算法的基石。我在生产环境用Faster R-CNN跑过一阵,精度确实高,但Titan X上也就勉强10fps,实时性还是不够。
3. 单阶段崛起:速度至上 (2016 - 至今)
两阶段方法精度虽高,但速度仍难以满足实时应用的需求。于是,另一条技术路线应运而生。
核心思想
取消区域提名阶段,直接在整张图上回归出物体的类别和位置。这种一步到位的方式,被称为**单阶段(One-Stage)**方法。
代表模型
YOLO (You Only Look Once) (2016)
-
思路:将图像划分为SxS的网格(Grid)。每个网格单元负责预测中心点落入其中的物体。
-
特点:结构极其简洁,速度飞快,真正意义上实现了实时检测。但早期版本对小物体的检测效果不佳。我第一次跑YOLO v1的时候,45fps的帧率确实震撼到我了——终于能实时了。
SSD (Single Shot MultiBox Detector) (2016)
-
思路:借鉴了Faster R-CNN中Anchor Box的思想,并在不同层级的特征图上进行预测。
-
特点:低层级的特征图分辨率高,适合检测小物体;高层级的特征图感受野大,适合检测大物体。在速度和精度之间取得了很好的平衡。我当时对比过SSD512和YOLO v1,SSD在COCO上的mAP高了将近10个点,速度也能接受。
4. 现代格局:百花齐放 (2018 - 至今)
随着研究的深入,单阶段和两阶段的界限逐渐模糊,新的范式不断涌现。
Anchor-Free 时代
-
背景:YOLO和SSD等方法都依赖于预设的锚框(Anchor Box),这些锚框的设计本身就是一组复杂的超参数,影响性能且不够优雅。
-
思路:抛弃锚框,回归到更本质的检测方式。
-
代表:
- CenterNet:将物体检测视为关键点(中心点)预测问题,然后回归其宽高。
- FCOS (Fully Convolutional One-Stage):直接在每个像素位置上预测其到目标边界的四条距离,非常直观。
Transformer 革命
-
背景:Transformer在NLP领域取得巨大成功后,研究者开始尝试将其引入CV。
-
代表:DETR (DEtection TRansformer) (2020)
- 核心思想:将目标检测视为一个集合预测(Set Prediction)问题。
- 流程:利用CNN提取图像特征,然后输入到一个Transformer的Encoder-Decoder结构中,直接输出一个无序的、固定数量的预测框集合。
- 颠覆性:它彻底抛弃了锚框和NMS(非极大值抑制)这两个在过去目标检测领域几乎不可或缺的手工组件,提供了一个极其简洁的端到端方案。虽然早期版本训练慢、对小物体不友好,但它开辟了全新的道路。我后来复现过DETR,训练确实比YOLO慢不少,500个epoch才收敛,但推理代码写得是真清爽。
总结
| 范式 (Paradigm) | 代表模型 | 核心思想 | 优/缺点 |
|---|---|---|---|
| 传统方法 | HOG + SVM | 滑动窗口 + 手工特征 | 缺点: 慢,鲁棒性差 |
| 两阶段 (Two-Stage) | Faster R-CNN | 先找候选框,再精细分类 | 优点: 精度高 缺点: 速度相对较慢 |
| 单阶段 (One-Stage) | YOLO, SSD | 直接在图上回归类别和位置 | 优点: 速度快 缺点: 早期精度稍逊 |
| Anchor-Free | CenterNet, FCOS | 抛弃锚框,用关键点或距离回归 | 优点: 结构更简洁,超参少 |
| Transformer | DETR | 将检测视为集合预测问题 | 优点: 抛弃NMS,端到端 缺点: 训练收敛慢 |
2D目标检测的演进之路,本质上是一个不断追求更高精度、更快速度、更少人工干预(End-to-End)的过程。从复杂的流程到简洁的端到端模型,这条路还在继续。我个人的看法是,现在YOLOv8和RT-DETR已经足够好用了,除非你有特别极致的精度或速度要求,否则没必要自己从头造轮子——调参的功夫,不如多搞点数据实在。