24GB 显存玩转 DeepSeek-R1:GRPO 原理与 Unsloth 踩坑实录

24GB 显存玩转 DeepSeek-R1:GRPO 原理与 Unsloth 踩坑实录
我去年年底开始折腾大模型微调,当时还在用 SFT + DPO 的老套路做指令对齐。效果还行,但一旦遇到数学题或者代码题,模型就开始胡说八道。试了很多次,发现这种组合在逻辑推理上确实有天花板。
后来 DeepSeek-R1 出来,把 GRPO 这个算法带火了。它不仅在推理能力上逼近 OpenAI o1,更重要的是把强化学习的门槛打了下来。我折腾了大概一周,才算是把这个流程跑通。这篇就记录下我的踩坑过程。
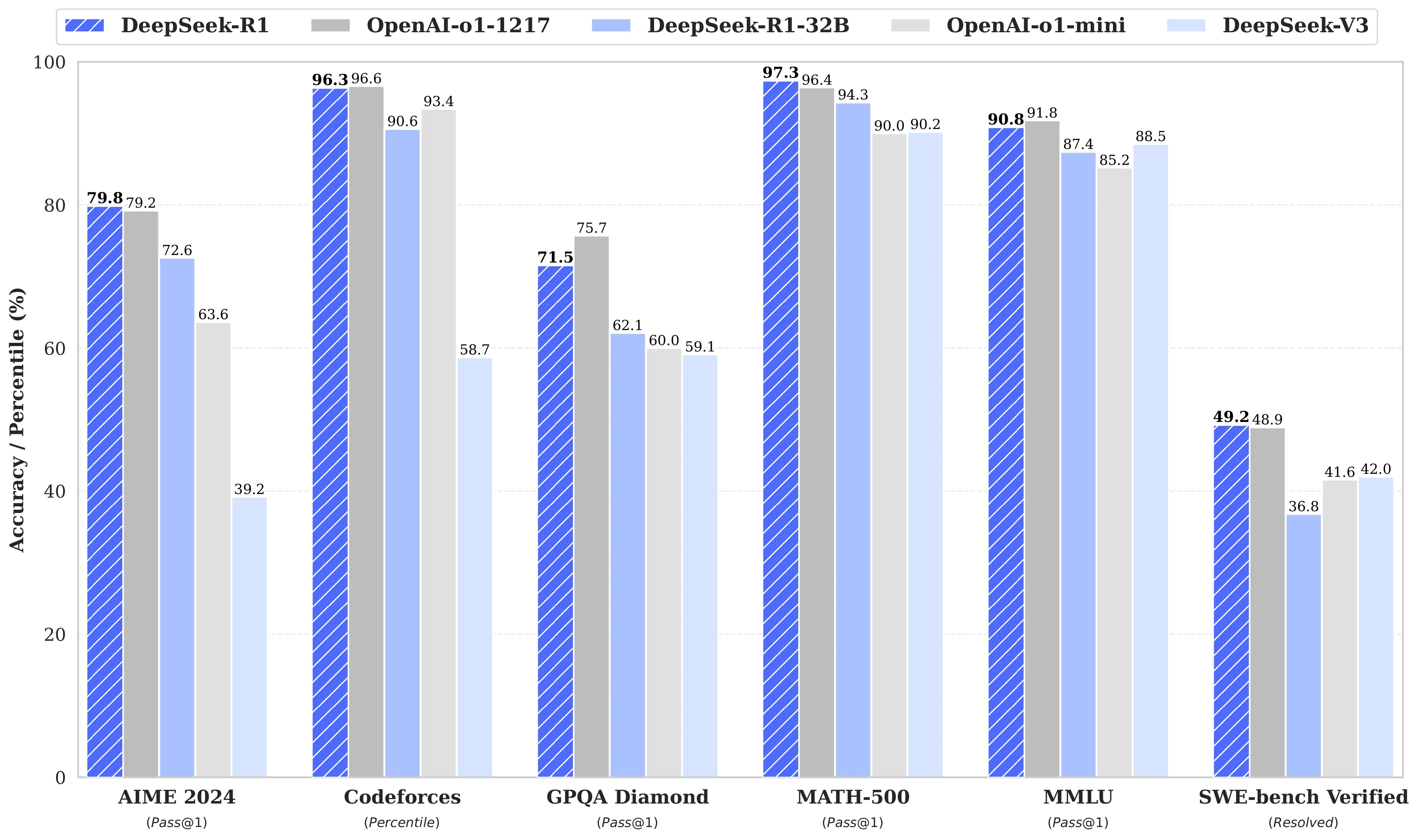 DeepSeek-R1 在各大基准测试中表现亮眼,背后的 GRPO 功不可没
DeepSeek-R1 在各大基准测试中表现亮眼,背后的 GRPO 功不可没
为什么放弃 PPO?因为显存真的不够
其实我一开始想直接用 PPO 的。毕竟那是传统 RL 的经典方案,理论上应该更成熟。但当我看到需要同时加载 Policy Model 和 Critic Model 两个模型的时候,我就知道这事在单卡 24GB 显存上干不了。
算了一下:一个 7B 的模型,FP16 模式下大概占 14GB 显存,两个就是 28GB。还没算 KV Cache 和优化器状态,OOM 是必然的。PPO 这种架构对 70B 级别的大模型来说,基本就是给大厂的集群准备的,个人开发者玩不起。
GRPO 的思路挺有意思——不搞独立的 Critic Model 了,直接对同一批 prompt 生成多个回答,然后让这些回答自己”内卷”。表现好的加分,表现差的扣分,简单粗暴但有效。关键是显存占用直接减半,24GB 的卡也能跑了。
实际训练下来,GRPO 在逻辑推理任务上的收敛速度确实比 PPO 快,而且训练过程更稳定,不会出现那种 loss 突然崩掉的情况。
GRPO 到底是怎么工作的?
说白了,GRPO 就是在每个训练 step 里做这么几件事:
- 针对同一个问题,让模型生成一组回答(比如 8 个或 16 个)
- 用规则奖励函数(比如代码能不能跑通、数学题答案对不对)给这些回答打分
- 计算这组回答的平均分
- 高于平均分的回答对应的生成路径被强化,低于平均分的被抑制
这个机制在数学和编程任务上特别好用,因为这两个领域有明确的客观标准。比如代码题,直接扔到解释器里跑一下就知道对不对;数学题可以用公式匹配来验证。
一个真实的训练案例
为了让你更直观地理解,我举个我训练时的例子。题目是:“如果 $x + 5 = 10$,求 $x$。”
未训练前的模型(SFT):
答案是 5。
GRPO 训练中期的模型(尝试生成 4 个样本):
- Sample A: “x = 10 - 5 = 5” (正确,奖励 +1)
- Sample B: “x = 10 + 5 = 15” (错误,奖励 -1)
- Sample C: “把 5 移到右边变减号,x = 5” (正确且有步骤,奖励 +1.2)
- Sample D: “x 是 5” (正确但无步骤,奖励 +0.8)
GRPO 会计算这组的平均分,然后发现 Sample C 这种”有推理步骤且结果正确”的模式得分最高(相对于平均值 Advantage 最大)。于是模型参数就会向”生成推理步骤”的方向更新。
慢慢地,我就观察到模型真的会”思考”了。不是那种装模作样的思考,而是会生成很长的 Chain of Thought,尝试不同的解题路径,最后才给出答案。这种能力不是人工教出来的,是强化学习自己探索出来的最优策略。
Unsloth:救命的性能优化
跑通 GRPO 只是第一步,真正的噩梦是训练效率。
我一开始用 Hugging Face 的原生实现,7B 模型在 24GB 显存上 batch size 只能设到 1,而且经常因为 KV Cache 溢出导致训练中断。一整个晚上就跑几个 step,心态直接崩了。
后来换了 Unsloth,情况完全不一样了。Unsloth 不是简单的封装,而是用 Triton 重写了反向传播的底层算子。我实测下来,同样的 7B 模型,训练速度提升了大概 3 倍,显存占用从 22GB 降到了 14GB 左右。
 Unsloth 官方给出的性能对比,实测确实能大幅节省显存并提升速度
Unsloth 官方给出的性能对比,实测确实能大幅节省显存并提升速度
关键是 Unsloth 支持 4bit 量化和 LoRA,这对我这种只有消费级显卡的人来说太重要了。以下是我实际用的配置:
from unsloth import FastLanguageModel, PatchFastRLfrom unsloth import is_bfloat16_supportedimport torch
# 启用强化学习补丁以加速计算PatchFastRL("GRPO", FastLanguageModel)
model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/Qwen2.5-7B-Instruct", max_seq_length = 2048, load_in_4bit = True, # 开启4bit量化,显存从22GB降到14GB fast_inference = True, # 启用推理加速)
# 注入LoRA适配器进行高效训练model = FastLanguageModel.get_peft_model( model, r = 16, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj"], lora_alpha = 16, lora_dropout = 0,)这里有个坑要注意:PatchFastRL 必须在加载模型之前调用,我第一次就是因为顺序搞错了,导致加速没生效,还以为是 Unsloth 版本问题,排查了半天才发现。
GRPO 不是什么都能干
折腾了一段时间后,我发现很多人(包括我自己)对 GRPO 有个误解:以为它能解决所有微调问题。
其实 GRPO 最适合的是那种有明确评判标准的逻辑任务,比如数学题、编程题。但如果你想让模型记住”开发者是谁”这种固定事实,或者修改模型的自我认知,GRPO 反而可能是错的工具。
我试过用 GRPO 训练模型记住特定的身份信息,结果模型确实记住了,但对话能力变得特别僵硬,问什么都是一个调调。后来改成用 SFT + 少量高质量样本 + 系统提示词约束,效果反而更好,成本也更低。
所以我的建议是:涉及”怎么思考”的问题,上 GRPO;涉及”我是谁”、“这是什么”的知识点,老老实实做 SFT。别为了追新技术硬上,最后效果反而不如老方法。
写在最后
GRPO + Unsloth 这个组合确实让个人开发者也能玩得起大模型的推理对齐了。我从最初的 PPO 方案碰壁,到换成 GRPO 跑通流程,再到用 Unsloth 解决性能问题,前后折腾了大概两周时间。
现在回头看,最大的收获不是把模型训出来了,而是理解了强化学习在 LLM 领域的真实边界。技术选型不能只看论文里的数字,还得结合自己的硬件条件和实际业务场景。
下一步我打算尝试用 GRPO 训练一个专门做代码审查的模型,看看在更复杂的代码理解任务上表现如何。如果效果不错的话,到时候再写篇新的分享。