不卷参数卷效率:小米 MiMo-V2-Flash 的架构创新
最近花了一点时间仔细啃了小米 LLM-Core 团队发布的 MiMo-V2-Flash 技术报告。说实话,在各家厂商都在疯狂堆卡、卷万亿参数的当下,看到一个 309B 参数但激活只有 15B 的 MoE 模型,还是挺让人眼前一亮的。
它给我的感觉不是那种”力大砖飞”的暴力美学,而更像是一场精密的”外科手术”——把显存占用和推理延迟压到了极限,性能却还要硬刚 DeepSeek-V3 和 Kimi-K2 这些大块头。
这就很有意思了。既然算力不够,那就得靠架构来凑。我把报告里几个最让我觉得”有点东西”的设计拆出来,咱们聊聊这里的门道。
激进的近视眼策略:混合注意力
这篇报告最让我意外的,是他们在 Attention 机制上的大胆——或者说”抠门”。
现在的长文本模型,恨不得把 100k、200k 的 Token 全部塞进显存里,生怕漏掉一点信息。但 MiMo-V2-Flash 反其道而行之,搞了个 5:1 的混合滑动窗口注意力机制(Hybrid Sliding Window Attention)。
什么意思呢?
绝大部分层(5/6)都被强制戴上了高度近视眼镜,窗口大小被压到了极小的 128。这意味着在这些层里,模型只能看到当前这 128 个 Token。
我的第一反应是:这视野未免也太窄了吧? 连个完整的长句都看不完,还怎么理解上下文?
但这样做的好处是显而易见的:KV Cache 的开销直接暴跌。计算复杂度从 $O(N^2)$ 被硬生生拉回了 $O(N)$。对于动辄几百 B 的模型来说,这省下的显存简直是救命的。
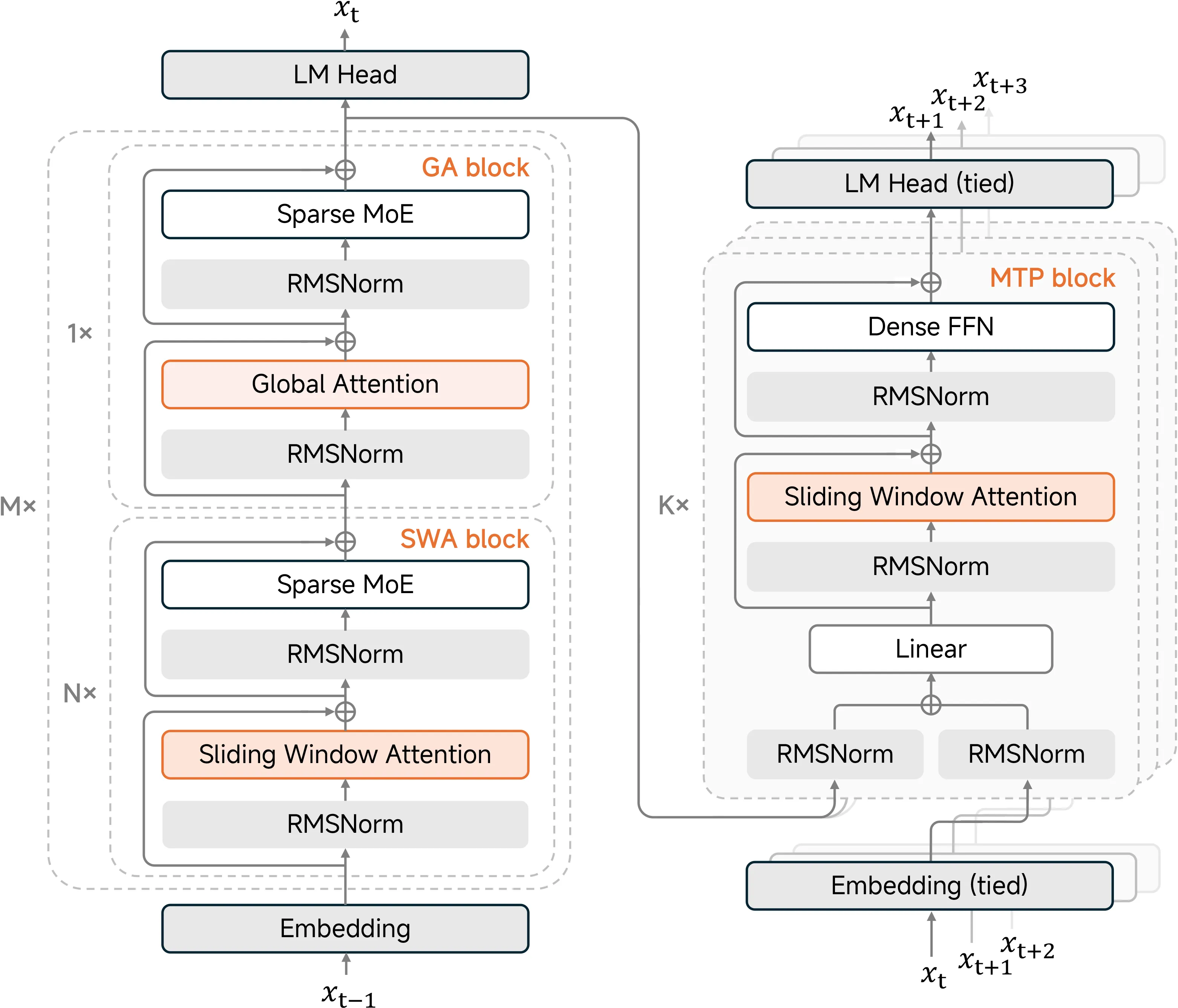 图1:MiMo-V2-Flash 的整体架构与混合注意力机制
图1:MiMo-V2-Flash 的整体架构与混合注意力机制
为了解决近视问题,他们每隔 5 层,就穿插 1 层 全局注意力(Global Attention)。这一层是用来”看全貌”的,负责把长距离的关键信息抓取出来。
这就好比你在看书:平时大部分时间你只关注眼前这一行字(SWA),但每读几页,你会停下来回顾一下整章的内容(Global Attention)。得益于 Transformer 的残差连接(Residual Connection),第 6 层抓取的全局信息会被扔进残差流这个”传送带”,第 7 层的 SWA 虽然眼睛只能看局部,但它背后的传送带里已经装好了全局上下文,推理依然顺畅。
这里还有一个很隐蔽的工程坑。强制模型只看 128 个窗口,很容易让注意力机制在处理开头 token 时数值崩溃(Attention Sink 问题)。他们引入了一个可学习的 Attention Sink Bias,简单说就是给注意力的汇聚点加个偏置,让它”有地儿可去”。这个小技巧让模型在 256k 的超长上下文里,检索准确率依然能维持在接近 100%。
MOPD:用”影分身”解决偏科难题
做过后训练(Post-Training)的同学应该都深有体会:模型往往有严重的”跷跷板效应”。你想让它代码能力变强,数学能力往往就会掉;你想让它逻辑严密,写作可能就变得干巴巴。
传统的做法是混合数据一锅炖,调配比例简直就是玄学。
MiMo 搞了一个 MOPD(Multi-Teacher On-Policy Distillation) 范式。我觉得这个思路非常聪明,它不强求一个模型全能,而是先练几个”偏科”的专家:
- 复制一个基座,狂喂数学题,练成数学专家。
- 复制一个基座,狂喂代码,练成代码专家。
- 再来一个逻辑专家。
这些专家在各自的领域都是刷到了巅峰状态的。
最后合体的时候,不是简单的参数平均(Model Merging),而是让原来的”学生模型”进行在线强化学习(On-Policy)。 学生在做题时,旁边的数学老师会手把手教:“这一步该这么推导”(提供 Token 级别的密集奖励);同时环境会给最终结果打分。
学生模型通过模仿这些偏科老师的 Logits,能同时学会多个老师的巅峰能力。这种”影分身修炼法”比单纯的数据混合要稳得多,而且因为是在线蒸馏,避免了离线数据分布偏移(Distribution Shift)的问题。
推理加速:买一送三
论文里提到了 MTP(Multi-Token Prediction),这个技术最近很火,DeepSeek 也在用。
原理很简单:主模型算完一个 Token 后,屁股后面挂着的轻量级 MTP 模块会瞬间猜出后面 3 个 Token。
为什么要这么做? 因为 GPU 计算是高度并行的,但推理是串行的。主模型算 1 个 Token 的时间,足够小模型猜 3 个了。 主模型不需要重新串行计算,而是把这 4 个 Token(1 个算的 + 3 个猜的)一次性扔进去并行验证。
- 猜对了?赚大发了,推理速度直接翻倍。
- 猜错了?也没损失,大不了扔掉重算。
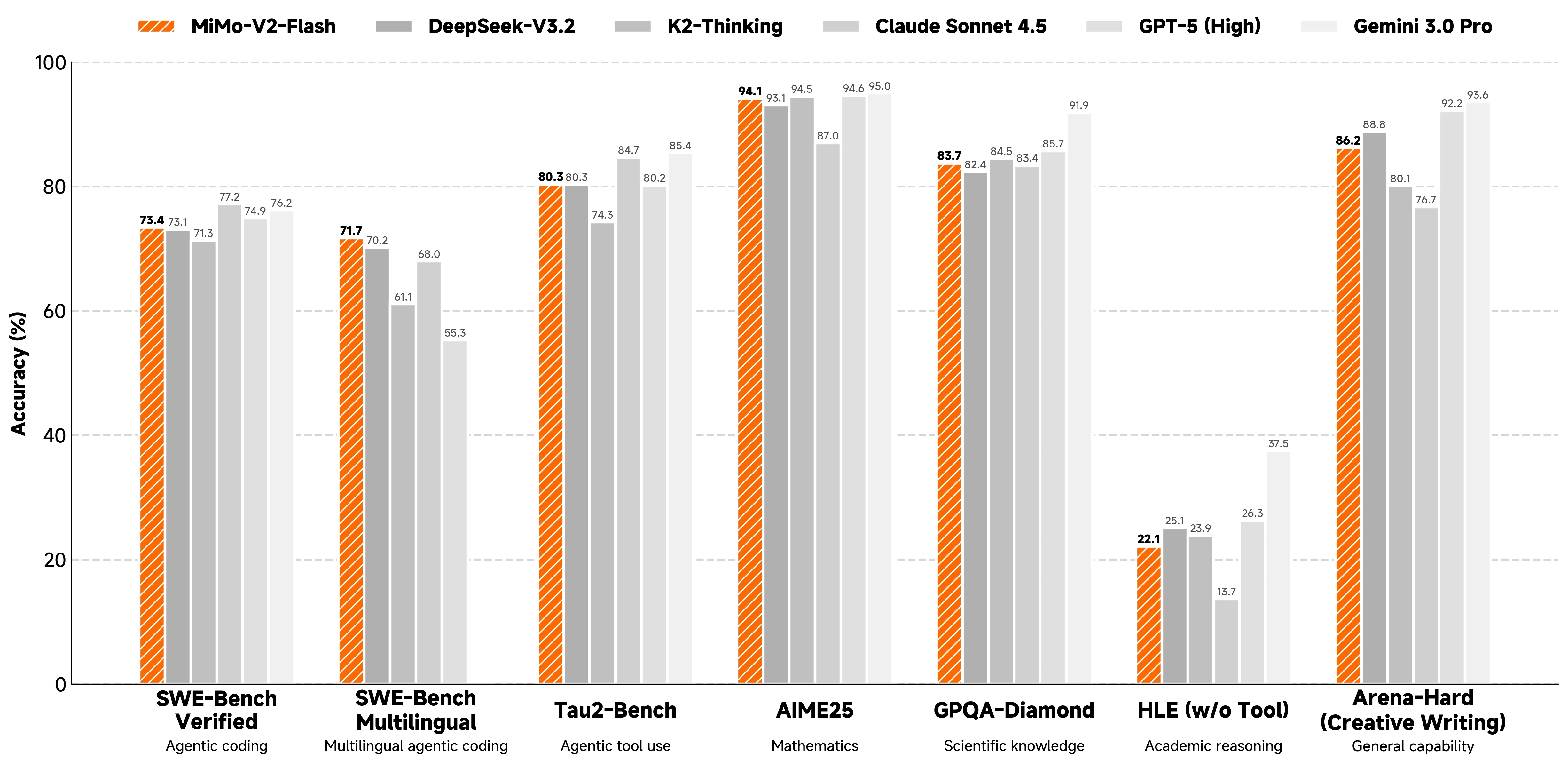 图2:MiMo-V2-Flash 在不同任务上的性能表现与推理加速效果
图2:MiMo-V2-Flash 在不同任务上的性能表现与推理加速效果
数据很漂亮:配合 3 层 MTP,平均能达到 3.6 的接受长度,解码速度提升 2.6 倍。对于强化学习中的 Rollout 阶段(这是最耗时的),这能大幅减少 GPU 的空转时间,提升训练吞吐。
训练稳定性的”隐形杀手”
在 MoE 模型的 RL 训练中,有一个很容易被忽视的深坑,论文里特别提到了:Rollout Routing Replay (R3)。
我们做推理(Rollout)时,为了速度通常用 FP8 甚至更低精度;但训练反向传播时,为了梯度稳定必须用 BF16。 这就导致了一个极其隐蔽的 Bug:
推理时,Router 觉得专家 A 和 B 最好,选了它们。 训练回传梯度时,因为精度差异,Router 突然觉得专家 C 和 D 更好。
结果就是:梯度传错人了! 你想奖励专家 A,结果梯度跑到了专家 C 那里。模型越练越崩,还没地方报错。
他们的解法简单粗暴但有效:在 Rollout 阶段把”用了哪个专家”死死记录下来,训练时强制复用这份路由记录。虽然增加了显存开销,但对于 MoE 的 RL 训练稳定性来说,这是必须付出的代价。
同时他们还监控了一个 num-zeros 指标(零梯度参数数量),用来预警专家的负载均衡情况。这些都是实战里用真金白银砸出来的经验。
写在最后
MiMo-V2-Flash 给我的启示是:当摩尔定律放缓,架构创新才是王道。
它证明了我们不需要一味地堆叠参数。通过精细的注意力管理、聪明的蒸馏策略和对工程细节的极致把控,中等体量的模型依然能爆发出惊人的战斗力。对于资源有限的团队或端侧部署场景,这或许才是更值得参考的路径。
注:官方 GitHub 仓库尚未更新权重下载链接。目前的测试数据建议参考论文中的 Figure 6 和 Table 9。我也在等代码开源,到时候再实测一波具体的推理速度。