GPT-5.5 重创 Anthropic?
GPT-5.5 横空出世
GPT-5.5 总算出来了,经过奥特曼一番打磨,万众期待(好吧至少我在等)。
先说钱,不便宜。API 输入 5 刀 / 百万 tokens,输出 30 刀,比 5.4 贵了,开了 xhigh 和 fast 以后更狠,20xpro 也扛不住,随便用用就见底了。但 OpenAI 那边的说法很清奇:这次模型指哪打哪,返修次数少了,所以理论上花的钱反而更少——这逻辑我品了半天,也不是完全没道理。修三次才对的活一次搞定确实省了,但前提是你得信它能一次搞定。
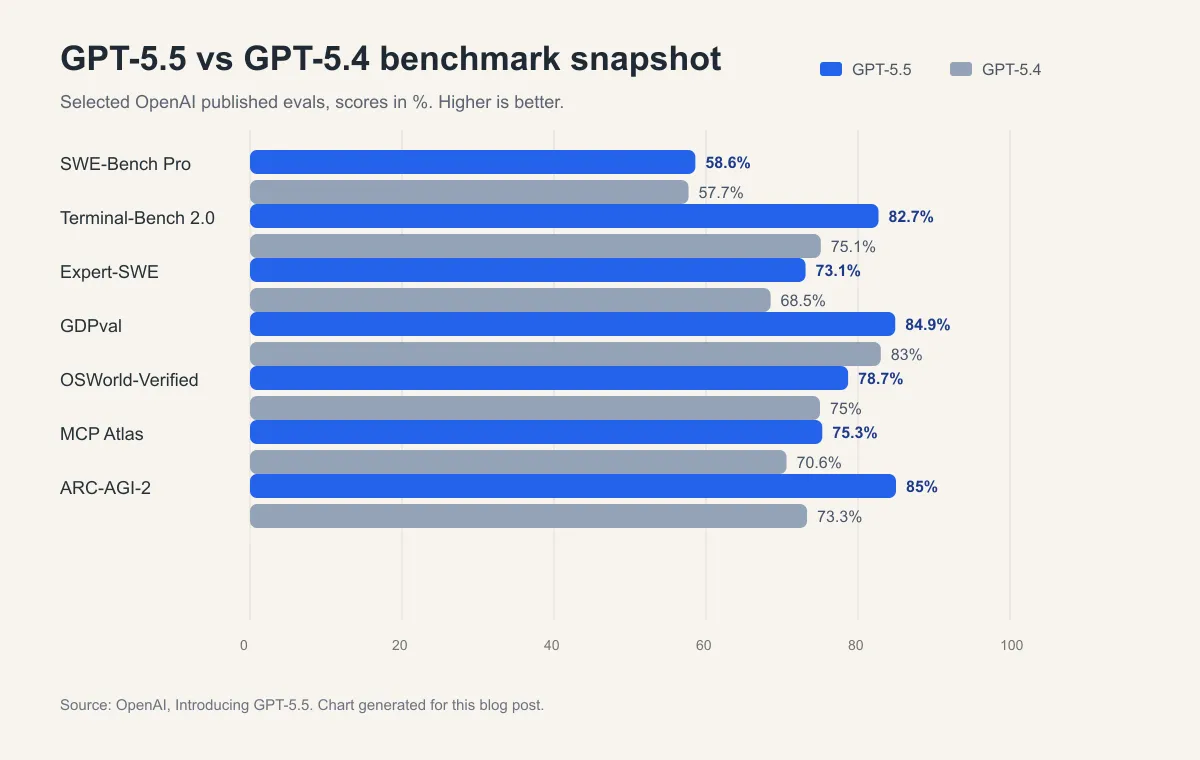
实际体感上倒是没骗人,GPT-5.5 跟 5.4 比最明显的就是更稳更不会瞎绕,代码场景尤其明显,让干嘛就干嘛,不会想半天憋一段分析然后改了一行注释算完。指哪打哪这个说法,这版倒是真沾边了。
OpenAI 与 Anthropic 的恩怨
说到 OpenAI 就绕不开 Anthropic。
先纠正一个常见误解:不是 Anthropic 的人离职创立了 OpenAI,方向是反的。OpenAI 2015 年成立,Anthropic 是 2021 年由一群 OpenAI 的前员工创立的——Dario Amodei、Daniela Amodei 兄妹带队,当时 Dario 是 OpenAI 的研究 VP。他们离开的原因主要是理念分歧,觉得 OpenAI 不够重视安全,于是自己出来干了。
从此两家就杠上了,人才互相挖,模型互相对标,发布会前后脚。有个江湖传闻说在某次会议上奥特曼不愿意跟 Dario 一起举手合影——我没找到确凿视频,但这种八卦能流传本身就说明火药味在。
跑分这边,GPT-5.5 对 Opus 4.7(Anthropic 最新旗舰):
坦白说我手里没有直接贴 GPT-5.5 vs Opus 4.7 的完整 benchmark 图。但从各方向跑分来看,GPT-5.5 在代码相关场景——SWE-Bench、Terminal-Bench——优势明显,OpenAI 的工程底子还在,Opus 4.7 在长文档理解、创意写作、推理链条上不弱,安全性也更符合 Anthropic 一贯的“宪法 AI”风格。两家现在是各有侧重,不是一方全面碾压。
我更喜欢 OpenAI,而不是 Claude
理由很简单:Anthropic 对华态度太激进。
23 年我就注册了 Anthropic,拿 Claude 润色简历,当时说实话效果比 GPT 和 Gemini 都好,我印象很深,但接下来就是三连封号——前后三个号,登陆秒封,没有任何解释。我不觉得这种态度是想要收集用户反馈,也不想在这种平台上继续投时间成本。
当然 Anthropic 后面官宣了:2025 年 9 月起停止向中国等国家控制的实体销售产品,理由是国家安全。行吧,理由归理由,体感就是不好。
转头用了 GPT,这几个月发展势头确实猛——OpenAI 公开的 benchmark 里,5.5 在 Terminal-Bench 2.0 上拿了 82.7%,FrontierMath Tier 1-3 是 51.7%,两项都压着 Opus 4.7 和 Gemini 3.1 Pro。英国 AI Security Institute 测下来,5.5 在专家级网络安全任务上通过率 71.4%,比 Claude Mythos 的 68.6% 高出一截。ZDNET 给了 93/100,评价是 agentic coding、概念清晰度、科研能力和知识准确性都有明显进步。日常体感也对得上——写代码更少返工,推理不会半路跑偏,理文档也能抓住重点。5.4 已经很好用了,5.5 更顺手,配合 Codex 开发我现在基本用它当主力。安全约束是有,但不像 Claude 那样动不动给你上政治课。
GPT-5.5 不是神,但指哪打哪是真的,希望再接再厉吧。
如果你有多个官方 / 中转站账号,常常要开很多窗口来管理不同的 agent session 上下文,推荐试试我的开源项目 pad——一个 tmux 里的 AI agent 工作台,一个界面管理所有 agent session,不用满屏找窗格,瞟一眼就知道哪个跑完了该接着干活。纯 Rust,3.7MB,两百多星,MIT 开源。
本文基于 2026-04-24 的公开信息和个人使用体感。