
GLM5的跑分保真吗?
GLM-5 这波声量很大。论文名字也很懂流量,直接叫「From Vibe Coding to Agentic Engineering」:别再让模型陪你一句一句补代码了,让它自己拆任务、跑工具、修问题。
我现在更关心的不是它某个榜单第几,而是三件事:跑分到底该怎么看,价格到底有多便宜,以及智谱上市后那条股价曲线有多离谱。
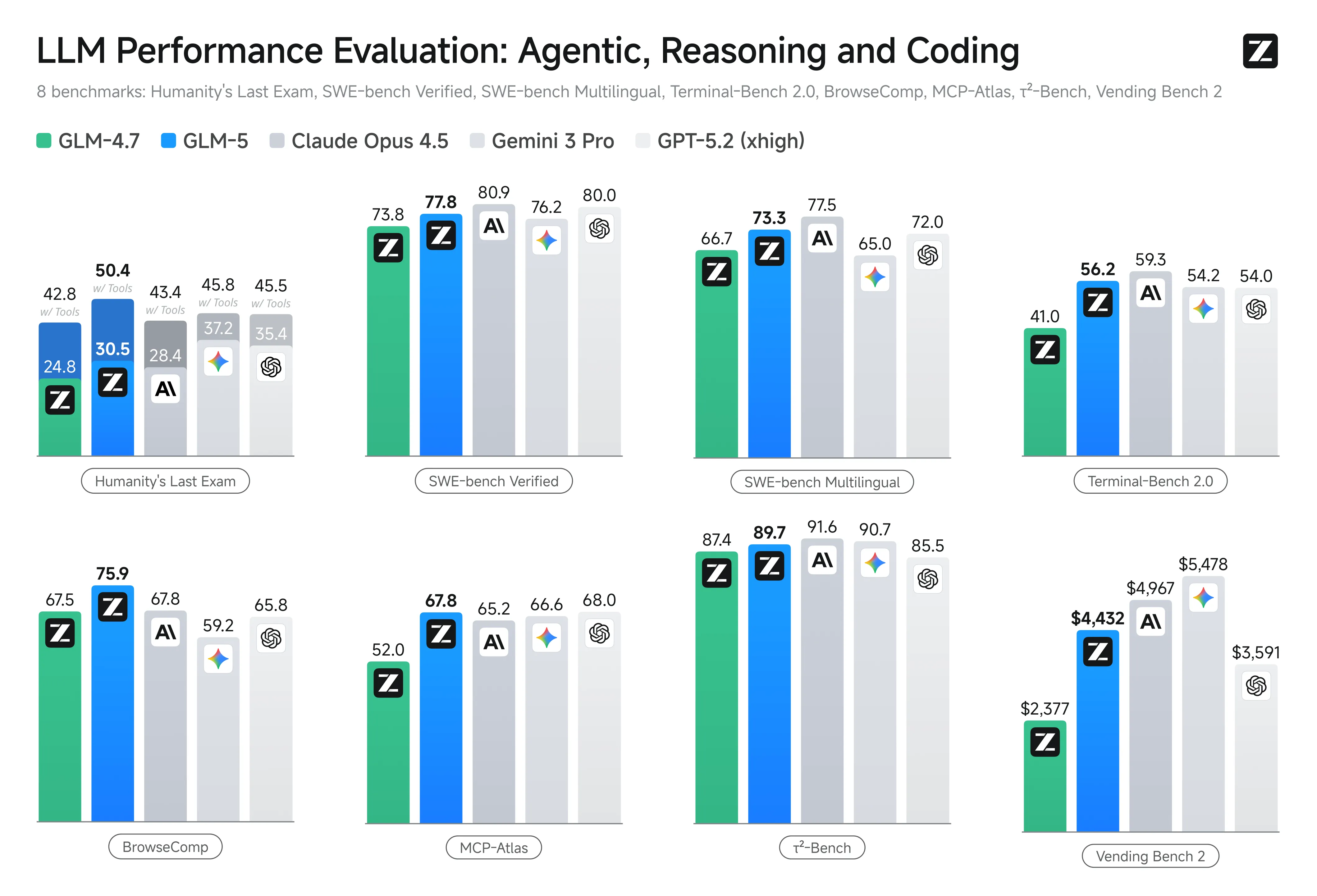
跑分与定价
GLM-5 的账面参数很夸张:744B MoE,总参数很大,但每个 token 只激活约 40B。官方文档里 GLM-5 是每百万输入 token 1 美元、输出 3.2 美元;后来的 GLM-5.1 是输入 1.4 美元、输出 4.4 美元。放到 agent 场景里,这个价格确实香,因为 agent 一跑起来就是几十轮上下文。

但我一直不太把跑分当成国模的唯一标准。不是说跑分没用,而是它太容易被训练数据、评测集污染、prompt 技巧和蒸馏争议影响。
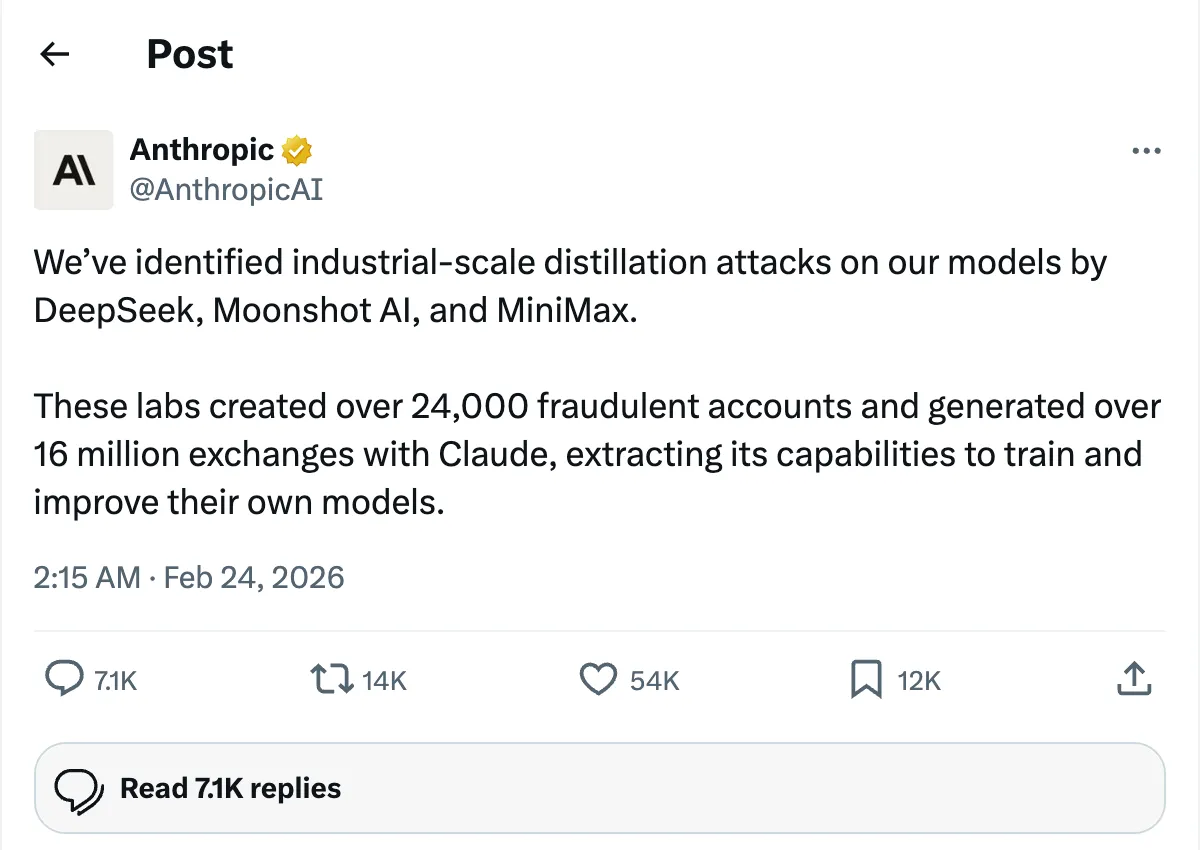
这里顺手纠正一个容易传歪的点:Anthropic 在 X 上公开说的是 DeepSeek、Moonshot AI、MiniMax 对 Claude 做了大规模蒸馏,并没有点名 GLM / 智谱。所以不能写成“GLM 被 Claude 官方实锤蒸馏”。但这张图确实解释了为什么大家看中文模型跑分时会天然打个折:行业信任本身已经被这种事消耗了一轮。
所以 GLM-5 的跑分我会这么看:能说明它值得上手试,不能直接说明它已经稳定替代 Claude。尤其是 agentic coding,最后看的不是榜单,是它在真实仓库里会不会乱改、会不会撞墙、会不会知道停下来问人。
模型本身降一档说
GLM-5 的技术点可以先不用讲太满:MoE、长上下文、异步 RL、agent 训练,这些都重要,但对普通使用者来说,最直接的感受是它开始像一个“便宜的大号代码 agent”。
能跑长任务,能调工具,能看大仓库,价格又低。这就够它进入很多人的日常工作流了。
但它也不是魔法。社区里对这类模型最常见的吐槽还是“莽”:目标给定以后一路冲,有时候不是不会写,而是不知道什么时候该停、什么时候该确认。省下来的 token 钱,可能会花在人工 review 上。
智谱母公司的股价
智谱现在对应港股的 Knowledge Atlas Technology / Z.ai,代码 2513.HK。它 2026 年 1 月 8 日在港交所上市,招股价 116.20 港元;我查到 2026 年 5 月 22 日收盘价是 1282 港元。
这就很有国内 AI 味儿了:模型发布,生态叙事,Agent 预期,股价一起飞。你说大家不懂 AI 吧,资金很诚实;你说大家很懂 AI 吧,这个倍数又有点像在给“国产 OpenAI”四个字上杠杆。
我倒觉得这部分比 benchmark 更有意思。GLM-5 真正带来的不是“某个榜单赢了 Claude 一点点”,而是它让市场相信国内大模型公司也能讲出一个清楚的商业故事:开源模型做声量,低价 API 抢开发者,企业私有化赚钱,Agent 产品承接想象力。
现在怎么用
如果只是聊天,没必要神化 GLM-5。如果是写代码、跑 agent、接到 Claude Code / OpenClaw 这类工具里,GLM-5 或 GLM-5.1 就很值得试。它最大的优势不是“最强”,而是“足够强,还便宜到你愿意多跑几轮”。