
GLM-5:从 Vibe Coding 到 Agentic Engineering,开源模型终于卷到这了
智谱发了 GLM-5,论文标题起得很大:「From Vibe Coding to Agentic Engineering」。简单说就是别再一句一句提示写代码了,让 agent 自己端到端搞定。
口号听多了容易免疫,但看完论文,这次智谱确实做了一些实在的东西。
先说结论
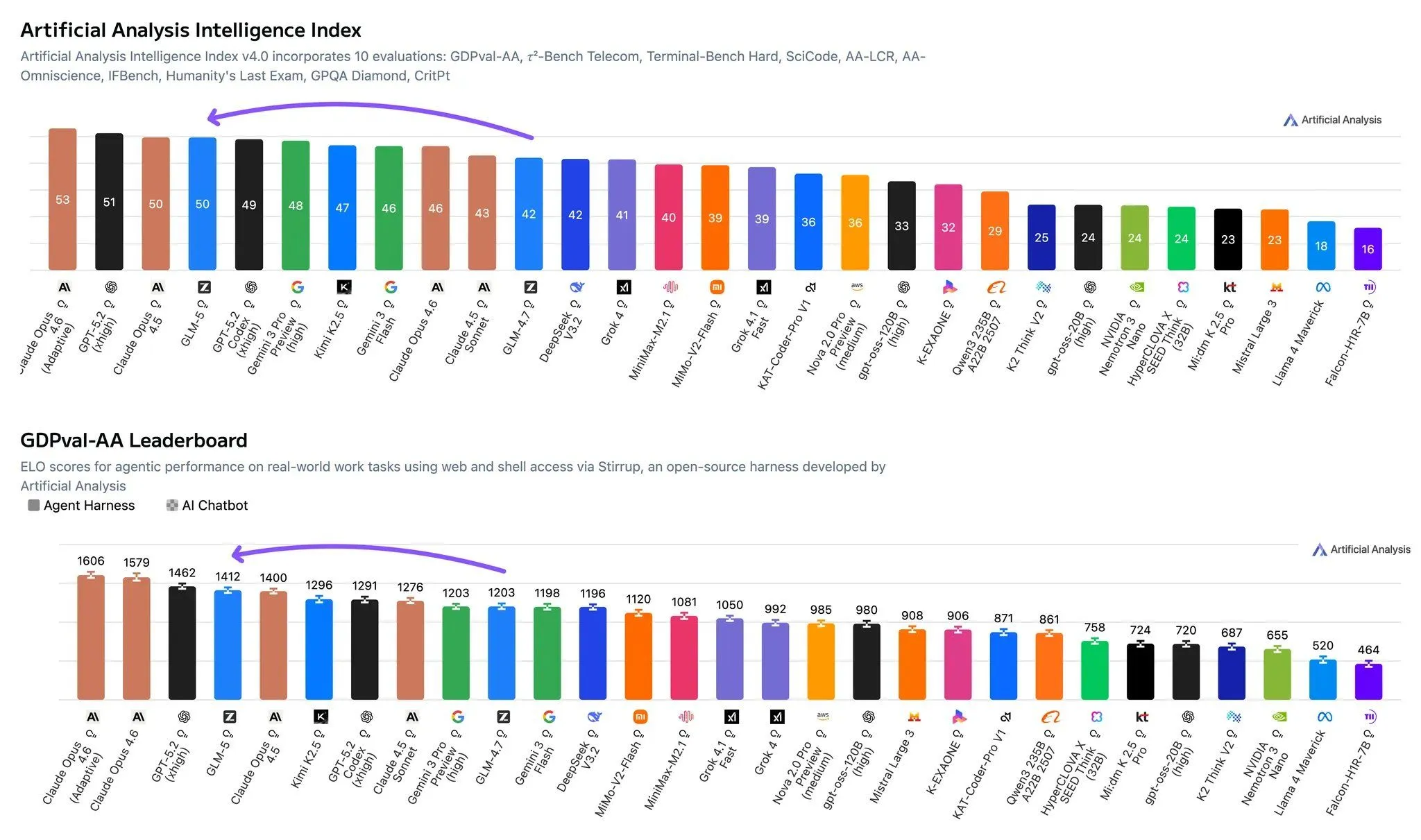
GLM-5 是目前开源模型里 agentic coding 能力最强的。SWE-bench Verified 65%+,Large Repo Exploration 65.6% 超过 Claude Opus 4.5 的 64.5%,Vending Bench 2 开源第一。
但它不是万能的。社区反馈最多的问题是这模型太“莽”了,给它一个目标它会不顾一切地往前冲,哪怕中间出了问题也不停。生产环境无人值守?还是算了。
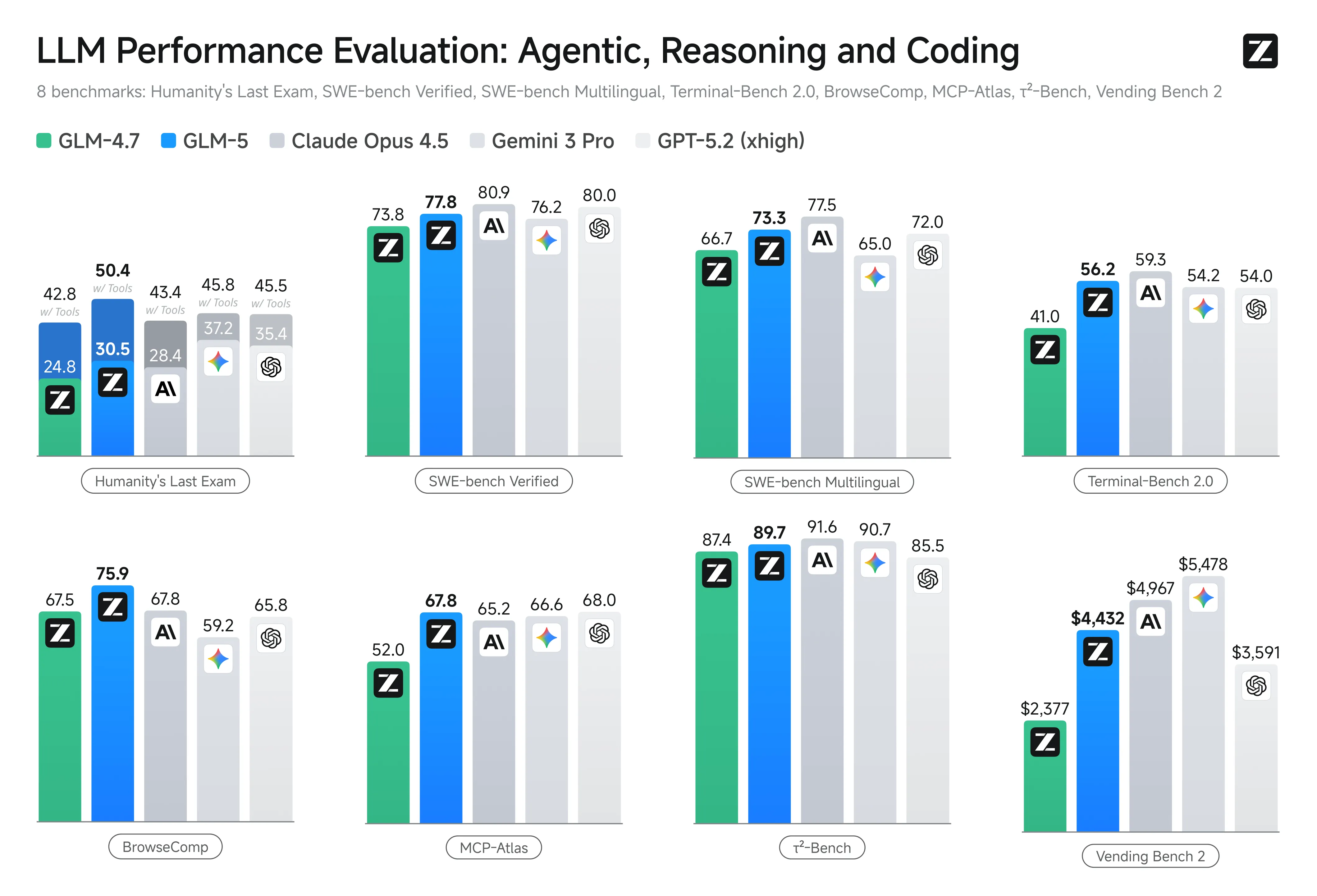
架构:744B 参数,只激活 40B
MoE 架构,总参数 744B,推理只激活 40B。比上一代 GLM-4.5(355B/32B)规模翻倍,推理成本没有等比增长。
关键改动是引入 DSA(DeepSeek Sparse Attention),动态选择重要 token 做 attention,长序列计算成本降低 1.5-2 倍。agent 任务动辄分析几万行代码,不解决长上下文成本问题,推理费用扛不住,这个设计很务实。
异步 Agent RL
论文里最有意思的部分是 RL 训练基础设施 slime。核心思路:把生成和训练完全解耦,生成端持续产出 agent 轨迹,训练端有数据就训练,不互相等。解决了传统同步 RL 里 agent 做长 rollout 时训练 GPU 干等的老问题。
后训练:三阶段 RL + 跨阶段蒸馏
SFT → Reasoning RL → Agentic RL → General RL,四步走。为了防止后面阶段忘掉前面学的东西,用跨阶段蒸馏把每个阶段的 checkpoint 都当“老师”,最后统一蒸馏。效果是 agent 能力上去了,基础对话和推理没掉。
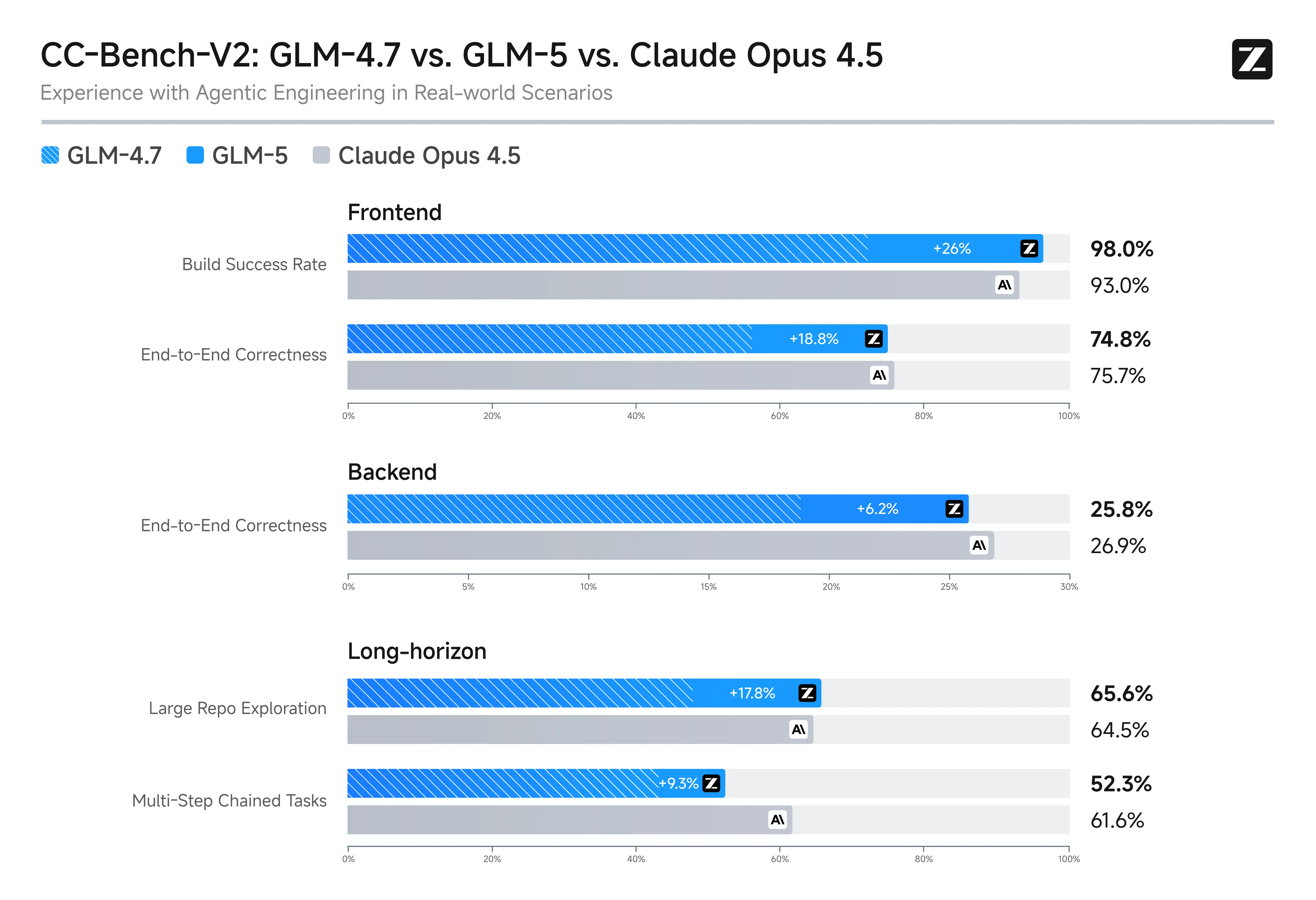
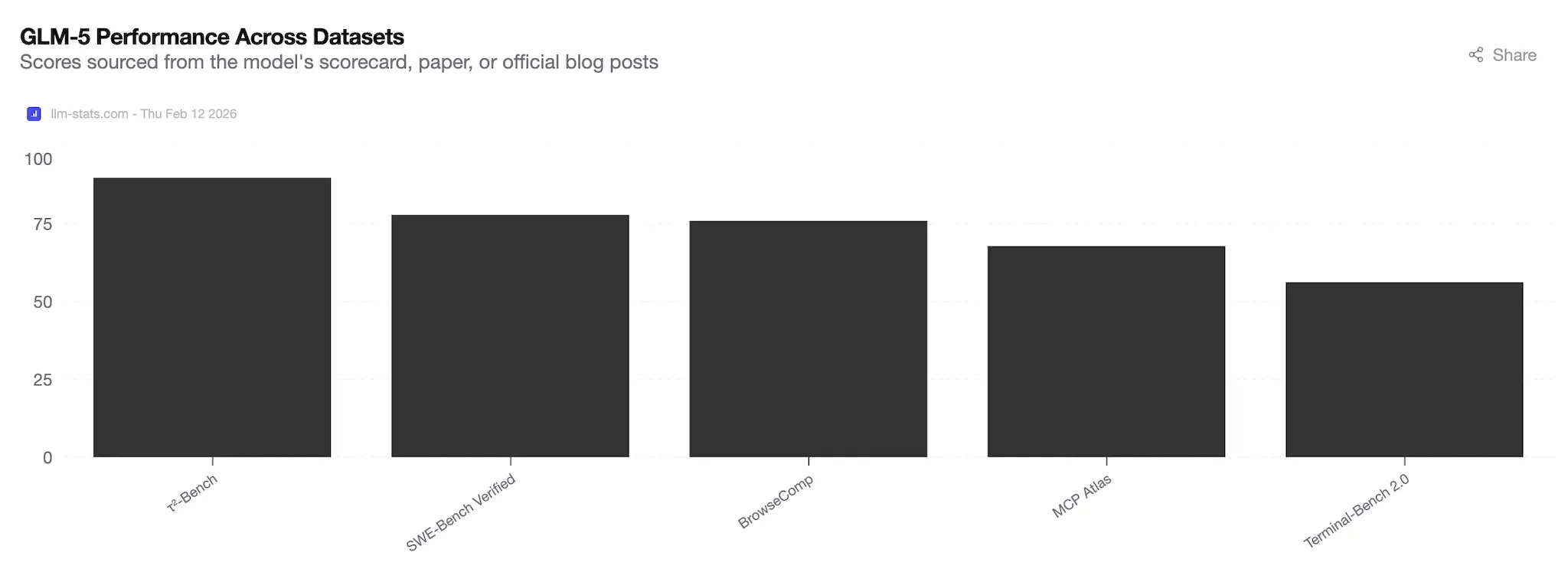
Benchmark 成绩
- SWE-bench Verified:65%+,开源第一
- Large Repo Exploration:65.6%,超过 Claude Opus 4.5(64.5%)
- Vending Bench 2:最终账户余额 $4,432,开源第一,接近 Claude Opus 4.5
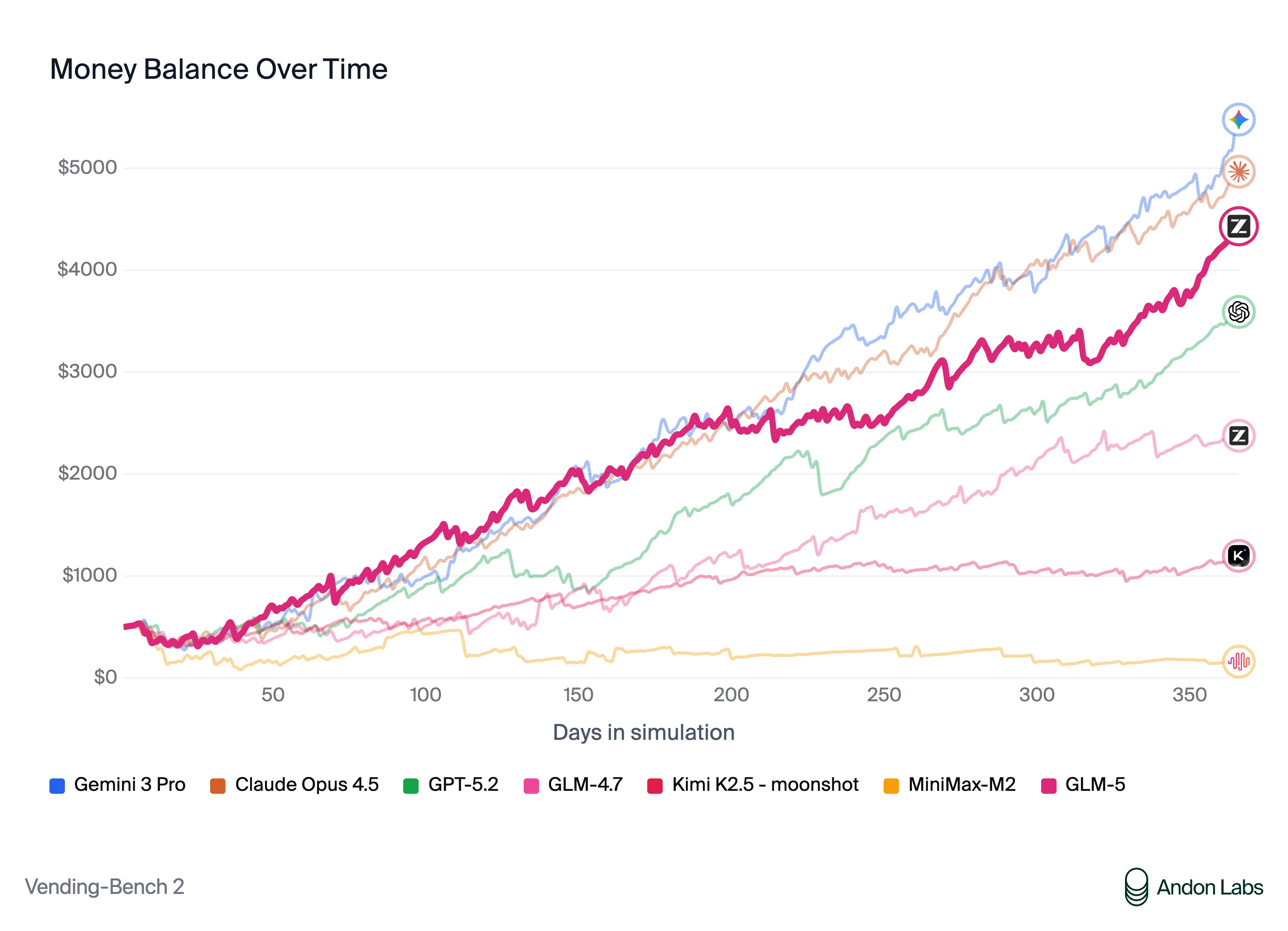
Large Repo Exploration 值得单独说。它要求模型在完全陌生的大型仓库里,根据业务语义描述找到特定文件,文件名故意起得很隐晦,藏在至少三层目录深处。这考的是真正的 agentic 信息搜索能力,GLM-5 在这上面超过 Claude,确实说明了一些东西。
定价:闭源的 1/5 到 1/8
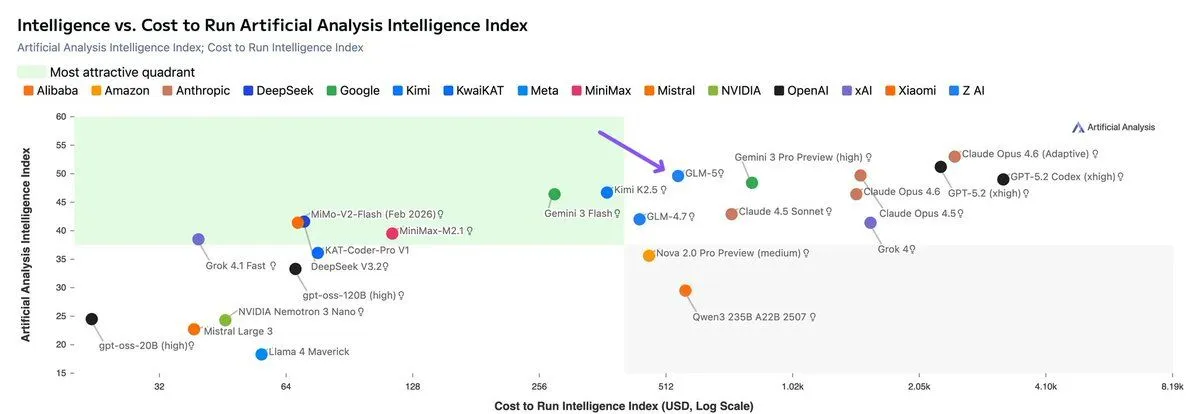
GLM-5 的 API 定价大概是 Claude 的 1/5 到 1/8。agent 任务一个 episode 跑几十轮对话,token 消耗量巨大,价格差距会被放大。
不过便宜归便宜,前面说了,这模型有”莽”的问题。省下来的 API 费用,可能要花在人工 review 上。

我的看法
GLM-5 这篇论文最大的价值不在于某个 benchmark 刷了多少分,而在于它展示了一套完整的 agent 模型训练方法论:DSA 解决长上下文成本,异步 RL 解决训练效率,跨阶段蒸馏解决遗忘问题,10,000+ 真实 SWE 场景做可验证训练数据。这套方法论可复制,其他开源团队完全可以借鉴。
至于“从 Vibe Coding 到 Agentic Engineering”这个叙事,方向是对的,但现阶段还是过渡态。真正的 agentic engineering 需要模型能自主判断什么时候该停下来问人,而不是一路莽到底。GLM-5 在能力上到了,在判断力上还差一截。
不过话说回来,这是开源模型第一次在 agent 任务上真正逼近闭源前沿。半年前这还不可想象。
基于 arXiv:2602.15763,2026-02-17 发布。