
Gemini 3.1 Pro 出来了,聊聊我的实际体感
昨晚刷 Twitter 看到 Google 发了 Gemini 3.1 Pro,ARC-AGI-2 跑到 77.1%,比上一代高了不少。第一反应是:又来?上个月 3 Pro 才刚稳定下来。
不过看完数据,我觉得这次值得单独记一篇。不是因为它一定比所有模型都强,而是性能、价格和长上下文这三件事放在一起,确实会影响我的使用选择。
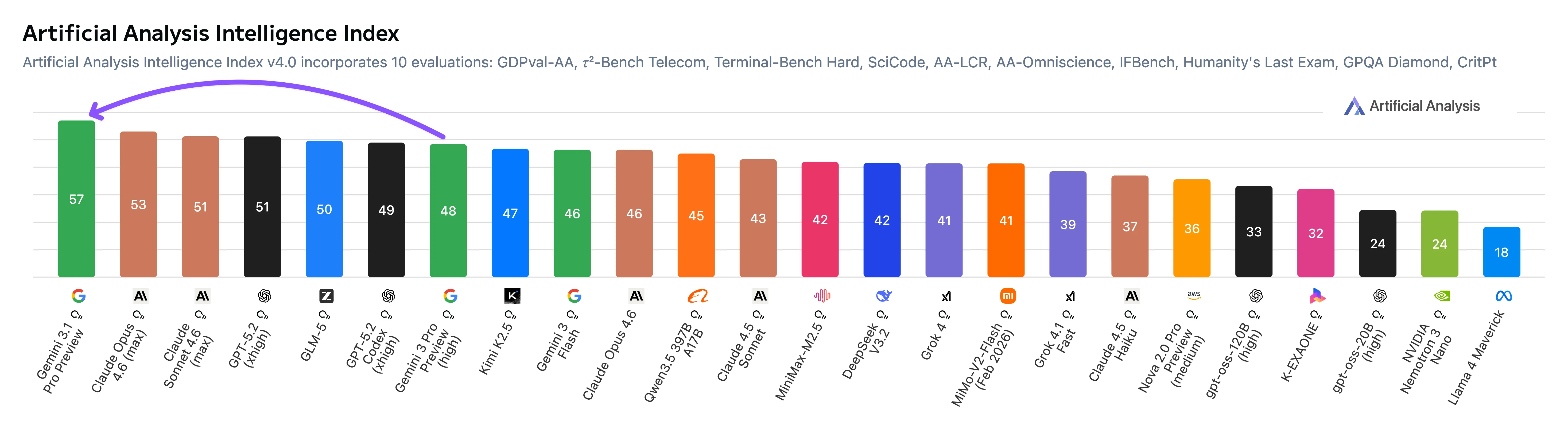
先看 ARC-AGI-2 成绩
ARC-AGI-2 这个测试比较特殊,它考的是模型碰到全新逻辑模式时的现场推理能力,不是背答案。人类平均水平大概 60-70%。
各家成绩:
- Gemini 3.1 Pro:77.1%
- Claude Opus 4.6:68.8%
- GPT-5.2:52.9%
- 上一代 Gemini 3 Pro:31.1%
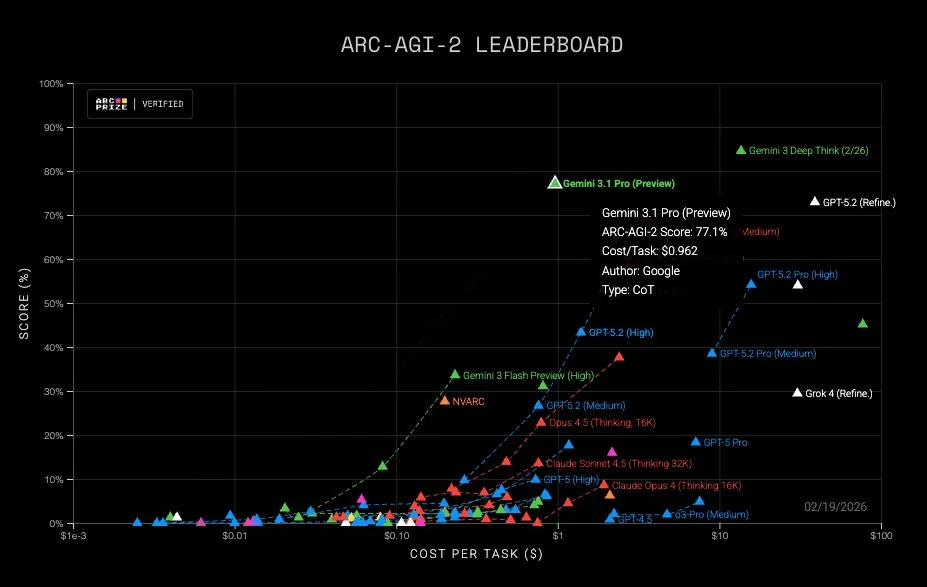
从 31% 到 77%,这个跳跃幅度很大。不过我对这个数字有点保留意见。ARC-AGI-2 的测试集不算大,发布方也可能针对这类任务做过优化。这个分数可以说明推理能力在变强,但不能直接等价成日常编码或文档任务的成功率。
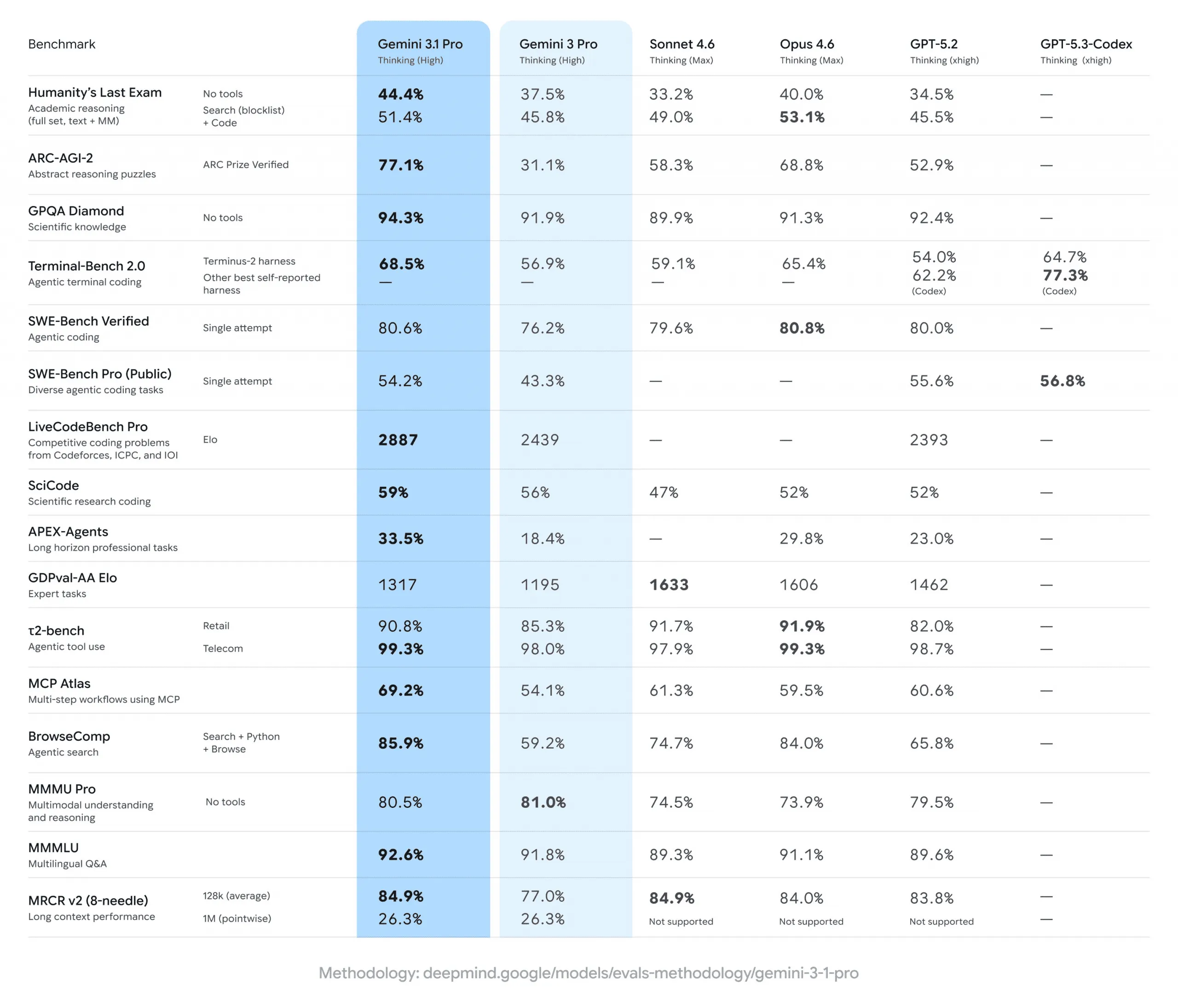
价格是主要优势
说实话,性能提升我没那么兴奋,真正影响我使用选择的是价格:输入 $2/M tokens,输出 $4-18/M tokens。
对比一下:Claude Opus 4.6 输入 $15、输出 $75,GPT-5.2 输入 $10、输出 $30。Gemini 便宜了 5-7 倍,性能还不差。
我拿一个实际的代码重构任务试了下。项目是一个 500 个文件左右的 Python 工具库,目标是把几处重复的数据清洗逻辑抽成公共函数,同时保证原来的 CLI 行为不变。
我的测试方式不算严谨,只跑了一轮:先让模型读目录结构和关键文件,再让它给修改计划,最后让它输出 patch。Gemini 这轮花了大约 $0.45,Claude 花了大约 $2.80。Claude 的修改更稳,边界条件考虑得多一些;Gemini 也能完成主路径,但漏了一个异常输入的处理。
如果只看这次任务,Claude 的代码正确率更高一点(我粗略估是 91% vs 87%)。但六倍左右的价差摆在那里,个人项目我会更愿意先用 Gemini 试一轮。生产环境另说,4% 的正确率差距在大项目里可能意味着几个小时的 debug。
思考模式的实际价值
3.1 Pro 加了三档思考模式——Low、Medium、High。我拿同一道逻辑题测了下,Low 模式 3 秒出结果,High 模式要 40 秒,准确率从 82% 到 94%。
听起来不错,但这个设计本质上就是让你自己选“花多少钱买多少准确率”。问题是,你在提问之前很难知道这道题该用哪档。我的做法比较保守:日常先用 Medium,遇到明显推理失败再切 High。这样会浪费一次调用,但比一开始全用 High 更可控。
1M 上下文的坑
1M tokens 的上下文窗口是 Gemini 的老优势了。我试了一份 600 页左右的技术手册,让它做跨章节引用,准确率大概 89%,比上一代好了不少。
但要注意,长上下文不等于“什么都往里塞就行”。我试过把一整个项目的代码全丢进去让它分析,结果它对中间部分的代码明显不如头尾敏感。这个问题不是 Gemini 独有的,所有长上下文模型都有类似的“中间遗忘”现象,只是程度不同。
踩到的坑
发布第一天就用,肯定有坑:
- 我的历史聊天记录升级后丢了一部分,社区里也有人反馈同样的问题
- High 模式下复杂任务响应时间 40-60 秒,偶尔会超时
- API 可用率体感大概 97% 左右,隔一阵就 500 一下,生产环境别急着上
这些都是新模型的常见问题,等两三周应该会好。
所以该换吗?
看你的场景:
适合切过去的:个人项目、原型开发、长文档处理、对成本敏感的批量任务。这些场景下 Gemini 3.1 Pro 的性价比很明显。
先别急的:生产环境、对代码正确率要求高的项目、需要稳定 API 的服务。等它稳定下来再说。
我自己的做法:日常探索和个人项目切到 Gemini,正经写代码还是用 Claude。不是说 Gemini 写代码不行,而是 Claude 在代码细节上确实更靠谱一点,这 4% 的差距在我的工作流里值那个价差。
Google 这个定价会给其他厂商带来压力。$2/M 的输入价格如果能长期维持,很多以前舍不得跑的长上下文任务,现在就可以更随便地试。
对我来说,这可能是 3.1 Pro 最直接的价值:不是每次都替代 Claude,而是把“先试一轮”的成本打下来。
数据基于 2026-02-20 测试,标准 API 调用,无特殊优化。