DeepSeek V4 发布一周后:便宜、开源、昇腾,以及那些被传歪的点
我一开始的记忆也有点混:最新是不是 R1?是不是 V3.2?是不是两个版本?是不是特别便宜?逆向限制是不是很小?还有大家最关心的一点:推理到底有没有用华为昇腾?
重新翻了一遍官方文档、模型卡和几篇报道后,结论比传闻朴素一点:V4 是最新主线,Pro / Flash 双版本,价格很狠,权重很开放;昇腾支持基本坐实,但线上 API 是否全量跑在昇腾上,公开资料没说死。
最新不是 R1,是 V4 Preview
DeepSeek 在 2026 年 4 月 24 日发布了 DeepSeek-V4 Preview。这次不是单模型,而是两个版本:
| 模型 | 定位 | 总参数 | 激活参数 | 上下文 |
|---|---|---|---|---|
| DeepSeek-V4-Pro | 旗舰版,复杂推理、Agent、代码 | 1.6T | 49B | 1M |
| DeepSeek-V4-Flash | 便宜、快、批量任务 | 284B | 13B | 1M |

所以“有两个版本”这个印象是对的。只是别和之前 V3.2 / V3.2-Speciale 混在一起。到 V4 这里,准确说法就是:Pro / Flash。
还有一个小细节:deepseek-chat 和 deepseek-reasoner 还在,但只是兼容入口,已经映射到 V4-Flash 的非思考和思考模式。官方写明,这两个旧入口会在 2026 年 7 月 24 日 15:59 UTC 后停用。
价格确实离谱
DeepSeek 这次最扎眼的不是参数,是价格。
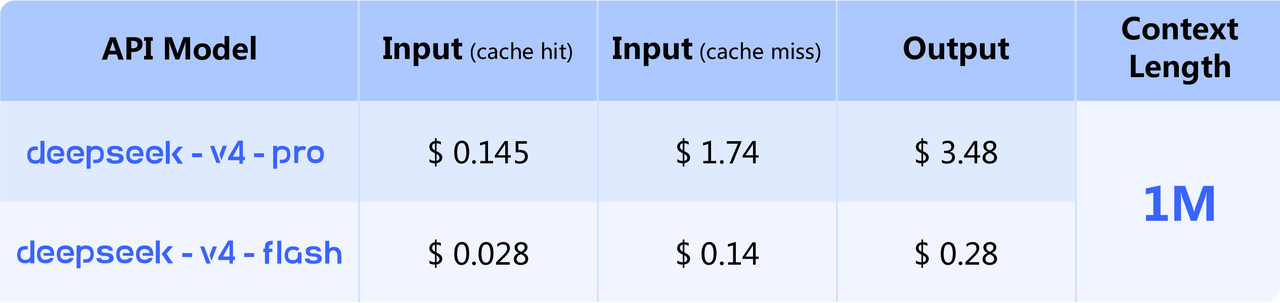
按 100 万 token 计费:
| 模型 | 输入缓存命中 | 输入缓存未命中 | 输出 |
|---|---|---|---|
| V4-Flash | $0.0028 | $0.14 | $0.28 |
| V4-Pro 折扣期 | $0.003625 | $0.435 | $0.87 |
| V4-Pro 原价 | $0.0145 | $1.74 | $3.48 |
Flash 的缓存命中价很夸张。长上下文、固定 system prompt、批量 Agent、重复前缀,这些场景如果吃到缓存,成本会被打得很低。
这也是推特上很多人第一时间盯着价格看的原因。不是它一定最强,而是这个价格会逼很多 API 中间层重新算账。
开源是真的,但别把 API 条款想得太松
V4-Pro 和 V4-Flash 的 Hugging Face 模型页都标了 MIT license。这件事很关键:你可以自己部署,可以改 serving,可以围绕它做本地推理栈。
但“权重开放”和“官方 API 没限制”是两件事。
DeepSeek 的服务条款仍然禁止未授权探测、扫描、漏洞测试、恶意程序、未授权访问,也禁止反向工程 DeepSeek 自己的服务、模型、算法和底层组件。
所以更准确的说法是:合法逆向、安全研究、CTF、本地部署会更自由;但不能理解成官方 API 允许随便做攻击或灰产。
另外,DeepSeek 对输出使用权写得比较宽。只要合法且遵守条款,输入和输出可以用于个人、学术、产品开发,甚至训练其他模型和蒸馏。这一点确实比不少闭源 API 更友好。
昇腾用了没?支持确认,全量推理未知
这个问题最容易被说过头。
能确认的是三点:
- Reuters 报道说,DeepSeek V4 面向华为芯片技术做了适配,华为芯片参与了 V4 的部分训练过程。
- 另有报道提到,华为 Ascend SuperNode 会支持 DeepSeek V4。
- vLLM-Ascend 已经给出 DeepSeek-V4 的部署文档,目前写的是先支持 V4-Flash,并给了 Atlas 800 A3 / A2 节点上的在线推理方式。
也就是说,“V4 能跑昇腾”“DeepSeek 和华为在 V4 上做了适配”“昇腾是这次发布叙事的一部分”,这些可以写。
但如果问:DeepSeek 官方 API 的推理是不是全量跑在昇腾上?
目前不能确认。DeepSeek 没公开线上 serving 集群硬件占比,也没公开 Pro / Flash 的硬件流量分配。更稳的写法是:昇腾参与和支持基本坐实;全量推理是否切到昇腾,公开资料不足。
性能:强,但别神化
官方图里,V4-Pro 的代码、数学、Agentic Coding 和长上下文成绩都很好。V4-Flash 更像成本优先版本,简单 Agent 任务很接近 Pro,复杂知识和复杂工作流会弱一些。
NIST/CAISI 的评估更冷静:V4 是他们评估过的最强中国模型,但整体能力大约落后美国前沿模型 8 个月;同时,它在相近能力区间里有明显成本优势。
这个评价我觉得比“吊打一切”靠谱:国模之光可以说,全面领先就别急。
推特上大家在聊什么
推特上这次最热闹的点,其实不是“V4 到底第几名”,而是“这价格是不是真的能这么打”。很多人盯着 Flash 的缓存命中价看,因为一旦放进 Agent、代码助手、批量处理这种场景里,账会变得很不一样。
另一个讨论是硬件。有人直接喊“摆脱 Nvidia”“全跑昇腾”,这个听起来很爽,但现在公开资料支撑不到这么满。能确认的是适配、支持、部分训练和可部署;至于 DeepSeek 官方 API 线上是不是全量跑昇腾,还没看到硬证据。
我身边也有人已经在用 DS4 跑自己的算法。他是把 DeepSeek 接进 VSCode 里的 Claude Code 插件,当代码助手用。看他的状态确实很爽:成本压力小,响应也够用,遇到一些工程代码、脚本改造、算法实验里的杂活,基本就是一路 yes yes yes 往前推。
所以我对这次社区情绪的理解是:大家不是只在夸模型聪明,而是在兴奋一件更实际的事——一个够强、够便宜、还能自己部署的模型,终于能被塞进日常开发流里用了。
参考资料
- DeepSeek V4 Preview Release
- DeepSeek Models & Pricing
- DeepSeek-V4-Pro Hugging Face 模型卡
- DeepSeek Terms of Use
- Reuters: DeepSeek V4 adapted for Huawei chip technology
- Reuters: Huawei Ascend SuperNode supports DeepSeek V4
- vLLM-Ascend DeepSeek-V4 部署文档
- AP: DeepSeek rolls out V4 update
- NIST/CAISI Evaluation of DeepSeek V4 Pro