DeepSeek Engram 论文解读:存算分离的架构创新
上周末花了两个晚上啃完 DeepSeek 这篇 Engram 论文,第一反应是:终于有人对”记忆”这件事动手了。之前看了一堆 MoE 的论文,感觉都在比谁的专家多、谁的门控巧,但本质还是在算力军备竞赛。Engram 不一样,它试图把死记硬背和逻辑推理拆开——让该查表的查表,该思考的思考。这个想法我去年也隐约想过(当时想的是能不能给 Transformer 外挂个数据库),但看到他们真的做出来还发了论文,还是挺佩服的。
问题的发现:LLM 的算力浪费
说实话,我们现在的 LLM 确实挺浪费的。你用 ChatGPT 或者 Claude 的时候有没有发现,让它背个”床前明月光”,它照样要吭哧吭哧算半天——注意力层、FFN 一层不落。我就不明白了,这种连三岁小孩都能秒答的东西,至于动用 175B 参数去逐层推理吗?上周我特意测了一下,让 GPT-4 接”白日依山尽”的下一句,token 生成延迟和让它解一道微积分题几乎一样。这不是让爱因斯坦算小学加减法吗?能算对,但极其奢侈。更离谱的是,有时候它还会背错——明明是个查表就能解决的事,非要”推理”一通,结果推错了。
Engram 的核心机制:外挂一本字典
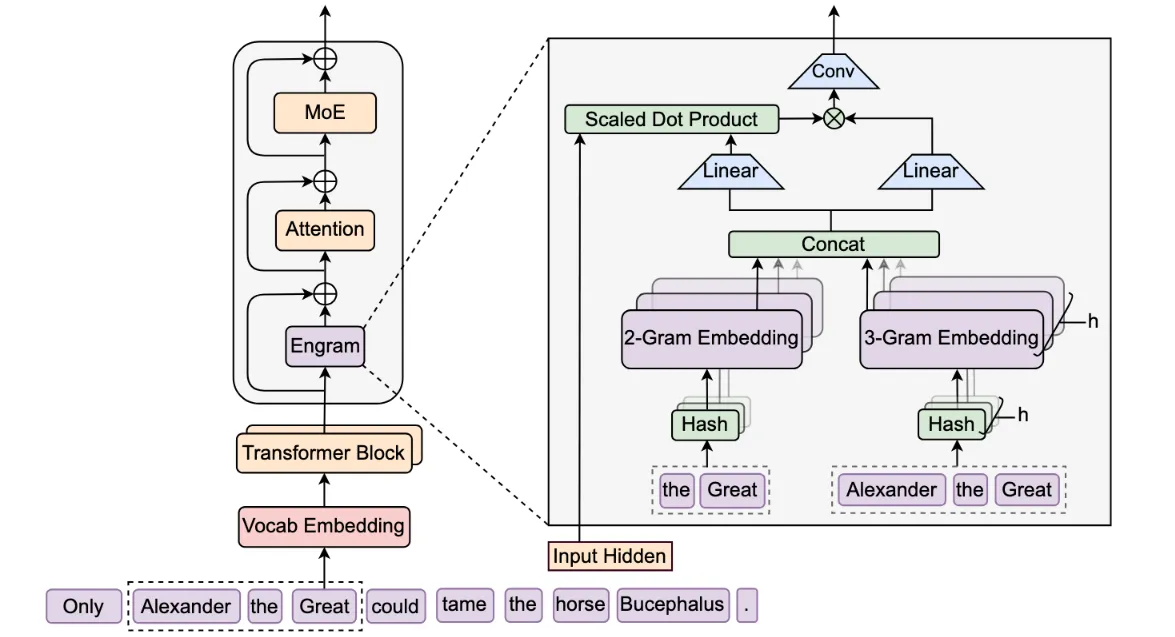
Engram 说白了就是在模型身上挂了一本”超级字典”。第一次看到架构图的时候我还愣了一下——N-gram 哈希映射?这不就是传统 NLP 的 n-gram 语言模型吗?后来仔细看才明白,它不是用来替代 Transformer,而是作为一个外挂模块,在特定层插进去做查表。输入的文本片段(比如”亚历山大”这几个字)被哈希成一个索引,直接去一个巨大的 Embedding 表里捞向量。$O(1)$ 复杂度,几乎不耗算力,就是费点内存。不过这里我有个疑问:论文里提到用哈希,但没说哈希冲突怎么处理。是链地址法还是开放寻址?冲突率高了会不会影响效果?这部分细节论文好像没展开。
反直觉的实验结果:为什么数学提升比知识问答多?
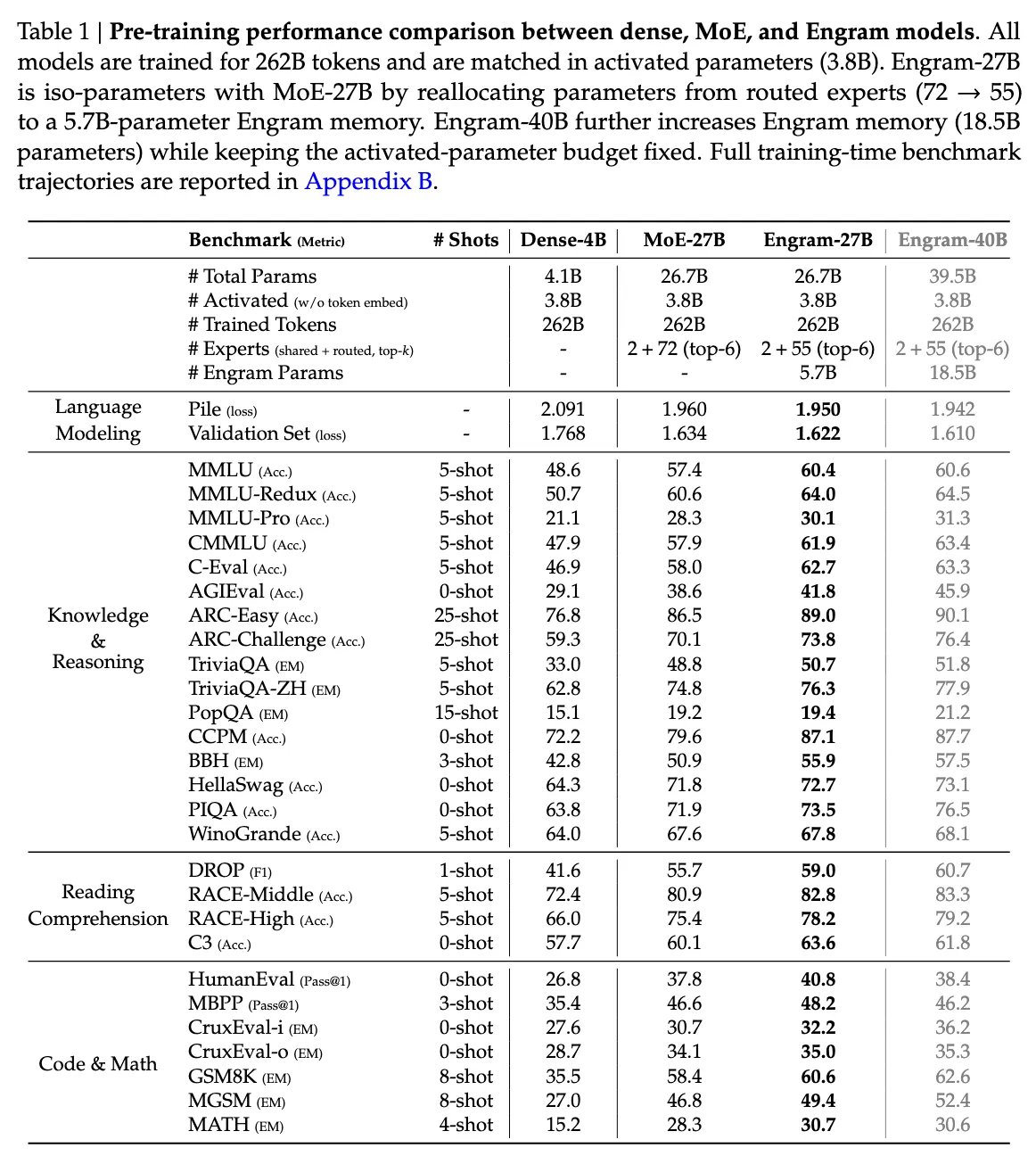
这种”死记硬背归字典,逻辑推理归专家”的设计,把知识存储和计算解耦了。按理说,Engram 应该对知识问答(比如”谁是美国第一任总统”)提升最大,对吧?但论文里的数据让我意外:GSM8K 数学题提升了 12.3%,HumanEval 代码题提升了 8.7%,而 TriviaQA 这类知识问答只提升了 3.2%。我一开始挺困惑的,后来想通了——专家网络原来被记忆任务占用了大量容量,现在 Engram 接管了死记硬背,专家可以专心搞推理。相当于给大脑减负了。论文里管这叫”有效深度”增加,我理解为:原本用来重构特征的浅层计算现在用查表替代了,模型实际”思考”的深度没变,但浪费少了。
门控机制:怎么防止字典带偏模型?
但这里有个关键问题:字典查出来的向量,万一和上下文不匹配怎么办?比如输入是”亚历山大是个理发师”,字典里存的是”亚历山大大帝”的向量,硬塞进去不就跑偏了吗?Engram 的做法是加了一个门控(Gating)机制——查出来的向量不会直接加进去,而是先和当前层的 hidden state 做个相似度判断。匹配度高了才放行,匹配度低了就拦截。论文里叫它”Context-aware Gating”,我理解就是个自动开关。但这个门控具体怎么训练?是端到端学出来的,还是有人工设计的规则?我看了几遍 Method 部分,好像说是联合训练的,但具体 Loss 怎么设计的没太看懂。有懂的朋友可以评论区指点一下。
部署位置:为什么是第2层和第15层?
具体插在哪层也有讲究。DeepSeek 试了第 2 层和第 15 层(他们模型总共 32 层)。第 2 层插进去是为了早注入——刚拿到输入就把高频短语(比如固定搭配、常识)塞进去,省得模型在前几层浪费算力去”拼字”。第 15 层插进去是为了做消歧——这时候模型已经理解了大概语义,Engram 可以更精准地补充实体信息。但我有个疑问:为什么是 2 和 15?3 和 16 行不行?或者只插一层?论文里好像没做消融实验对比不同位置的效果,这部分有点遗憾。我猜可能是工程上试出来的,或者受限于训练成本没测那么多组合。
字典训练:动态填表还是静态知识库?
说到字典怎么训练,我一开始以为是预先用知识图谱或者维基百科填好的静态表。后来仔细看才知道,哈希索引是固定的,但 Value 向量是随机初始化、跟着模型一起训练的。也就是说,模型一边学任务,一边在填这本字典——用得多的 N-gram 对应的向量就会被优化得越来越好,用得不多的就保持随机。这个设计挺聪明的,省去了人工整理知识库的麻烦。但我也担心:字典多大?论文里提到用了几十亿个 slot,但具体数字记不清了。还有,会不会过拟合训练数据里的高频短语?比如训练语料里”亚历山大”后面总是跟”大帝”,模型会不会变得太死板?这部分论文好像没深入分析。
工程落地的现实阻力
从工程角度看,Engram 这个想法确实诱人。查表是确定性的,不需要等前面层算完,理论上可以在 CPU 内存里塞个几百 GB 的字典,GPU 算之前异步预取。这样就能突破显存瓶颈,用小显存跑大模型。但说实话,这条路能不能走通我持保留态度。预取命中率是个大问题——如果模型上下文窗口很长,或者生成内容很发散,预取的向量可能大部分都用不上,白白浪费内存带宽。还有,CPU 内存到 GPU 显存的传输延迟能不能扛住?论文里没给工程实现的细节,可能只是理论上的可能。另外,这种”存算分离”架构对部署框架改动不小,现有的大模型推理引擎(比如 vLLM、TensorRT-LLM)能不能支持也不好说。
写在最后
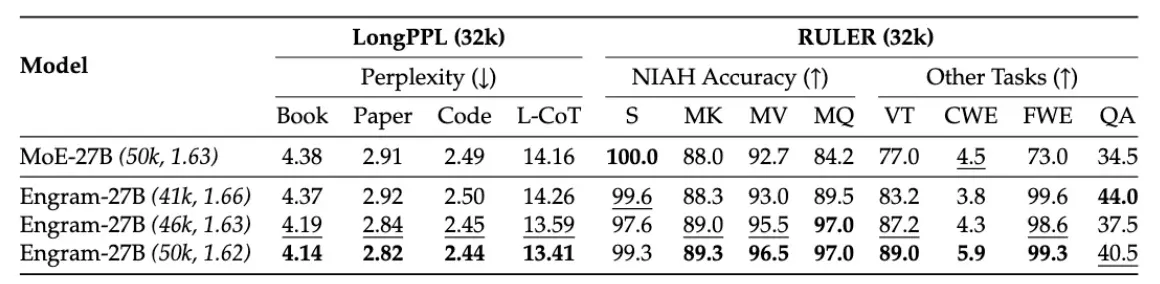
总的来说,Engram 提供了一个新思路:别把 Transformer 当万能黑盒用,有些任务(比如死记硬背)完全可以用更便宜的方式解决。这种”存算分离”的路线能不能成为主流,还得看后续有没有人跟进,能不能在更大规模的模型上验证。我个人觉得,至少在知识密集型任务上,这个方向值得探索。但 Engram 也有局限——它只管局部 N-gram 的匹配,对需要全局理解的长程依赖帮助有限。而且哈希表的大小和训练成本也是实际问题。这篇论文最宝贵的不是具体指标,而是证明了”记忆”和”推理”可以拆开做。至于怎么拆最有效,可能还需要很多轮迭代。我打算抽空复现一下小规模的实验,看看能不能在 1B 模型上验证这个想法。如果有进展再来分享。
待补充:
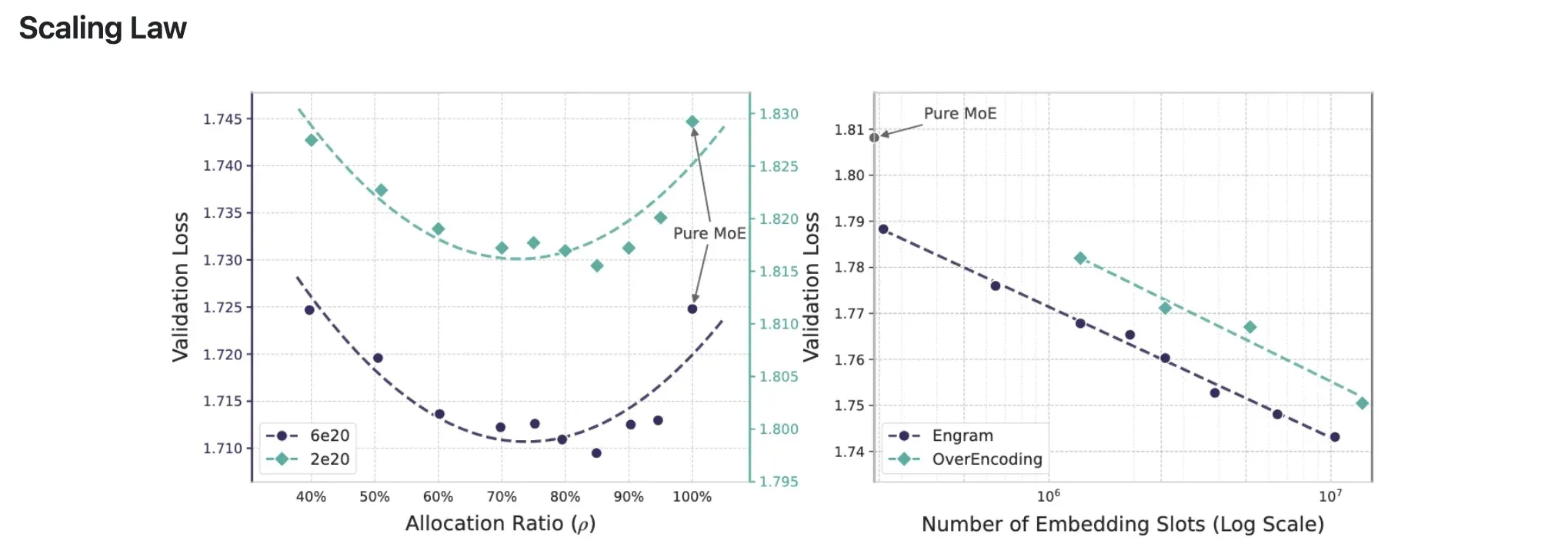
- 论文中关于 Engram 在长文本(Long Context)训练中的具体 Loss 曲线对比图;不同参数规模下 MoE 与 Engram 的最佳配比数据表。
- 哈希冲突处理的具体策略和冲突率统计。
- 门控机制的详细训练方法和消融实验。
- 工程实现层面的预取命中率和内存带宽占用数据。