低算力成本的新秀 Unsloth
我现在再看 Unsloth,最核心的感受不是“又一个训练框架”,而是它把很多原本只适合大机器的玩法,往个人显卡、Colab、Kaggle 这类低算力环境里压了一层。
Unsloth 为什么广受欢迎
Unsloth 火起来,主要还是两个字:省卡。
官方自己的说法是,Unsloth 可以让训练和 RL 在 500+ 模型上做到最高 2 倍速度、最多 70% 显存节省;GRPO 这类 RL 场景也主打更低显存。这个数字不用神化,但方向很明确:它不是在卷“我比谁更大”,而是在解决“我手里就一张消费级卡,还能不能动手跑一下”。
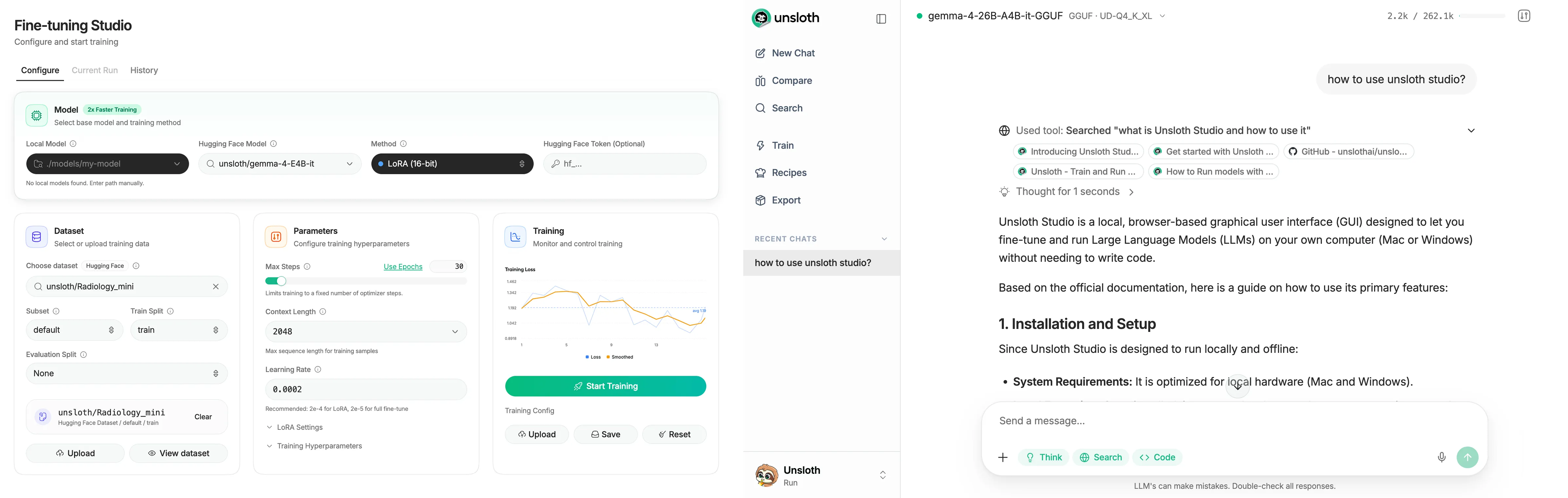 Unsloth Studio 官方界面,来源:Unsloth GitHub README
Unsloth Studio 官方界面,来源:Unsloth GitHub README
它不只做训练。现在 Unsloth Studio 已经把本地运行、训练、导出放到一起了:可以跑 GGUF、LoRA adapter、safetensors,也能导出到 GGUF、16-bit safetensors,或者接 Ollama、vLLM、llama.cpp 这类推理链路。严格说,Unsloth 不是要替代 vLLM/Ollama,而是更像一个“低门槛入口”:训练、试跑、导出、接本地 API,一套都帮你顺手串起来。
所以它受欢迎很正常。对大厂来说,这可能只是工程优化;但对 AI 爱好者、小团队、独立开发者来说,就是从“看论文”变成“我今晚能不能在自己机器上跑起来”。
GRPO 等训练方法的集成
Unsloth 不是一种训练算法,它更像是把常见训练方法做了低显存封装和加速。
SFT 它当然支持,这也是最基础的微调方式:给 prompt 和标准答案,让模型逐 token 学。除了 SFT,偏好对齐里常见的 DPO、ORPO、KTO,Unsloth 文档里也单独放了入口;RL 方向则重点推 GRPO、GSPO,以及 vision RL、长上下文 RL、FP8 RL 这些扩展。
 GRPO 的组内相对奖励示意,来源:Unsloth RL 官方文档
GRPO 的组内相对奖励示意,来源:Unsloth RL 官方文档
GRPO 这波出圈,确实和 DeepSeek 有关系。更早 DeepSeekMath 就已经提出过 GRPO;到了 DeepSeek-R1 / R1-Zero,GRPO 又被放到推理强化学习里,大家才真正开始重视这条线。
它和 SFT 的区别很简单:SFT 是“照着标准答案学”,GRPO 是“同一道题生成多个答案,用 reward 比谁更好,然后让高分答案的概率变高”。它不需要单独的 critic model,比 PPO 轻一些,所以特别适合数学、代码、工具调用、结构化输出这类 reward 比较好写的任务。
如果拿我们最近做的 bbox JSON 输出来类比,SFT 会纠结 token 顺序,object 先后换一下 loss 就可能很难看;GRPO/RL 更自然一点,因为它可以直接按 schema 合法性、类别、数量、IoU、重复框、空输出这些业务指标给 reward。前提是 reward 要写得稳,不然模型也会很快学会钻空子。
参考:Unsloth GitHub README、Fine-tuning Guide、RL Guide,以及 DeepSeek-R1 技术报告。