
深度、宽度、最大通道数
ultralytics使用yaml中的scales来获取深度、宽度和最大通道数
if scales:
scale = d.get("scale")
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
depth, width, max_channels = scales[scale]其中的scale来源于guess_model_scale
return re.search(r"yolov\d+([nslmx])", Path(model_path).stem).group(1) # n, s, m, l, or xre学习:http://www.tonwork.fun/index.php/2024/05/10/re/
其中scales在yaml中的内容如下:
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs网络模型
- 通过便利读取
yaml文件中的fromrepeatsmoduleargs内容获取网络模型信息
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
m = getattr(torch.nn, m[3:]) if "nn." in m else globals()[m] # get module其中通过getattr获取torch模块中带有nn.xxx的网络结构,如果不包含nn.网络结构则在globals()模块查找,globals会返回一个字典,包含全局的方法,使用[]传入需要查找的内容即可。
- 遍历
args字段
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)contextlib.suppress(ValueError)用于抑制with代码块下的所有跟Value Error相关的内容
如果a内容在本地变量中则返回这个变量,否则返回字面值。
我看了一下v8的yaml,其中含有”str”的args,只有str=”nearest”一种
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]module的重复次数
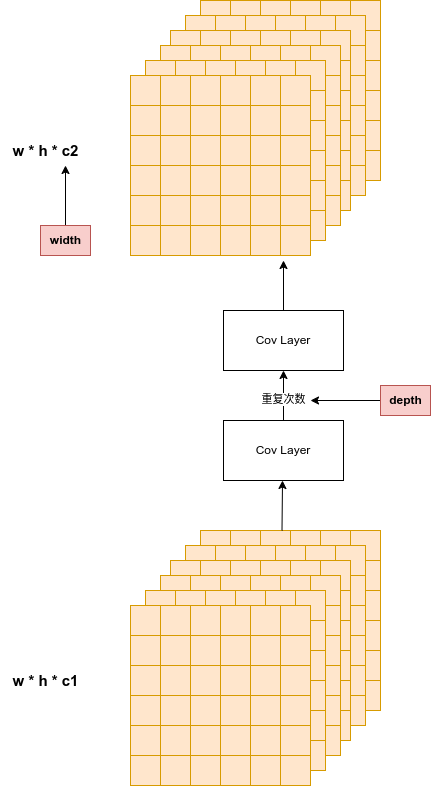
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain如果重复次数n大于1,则会跟depth相乘
- 通道数的确定
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)一般来说from都为-1,即:ch数组的最后一个通道数。输入为上一整channel数,输出通道数为args[0]与width的乘积。
注意:depth与module的重复次数相关,width与module的输出channel数相关
- args排序整理
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3}:
args.insert(2, n) # number of repeats
n = 1[64, 3, 2]变成[c1, c2, 3, 2]再insert(2, n),即:[c1, c2, n, 3, 2]
- TODO:Concat 与 Detect
- 统计变量
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, type统计参数量、序号等等
- 将
savelayersch统计
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)save的作用不太清楚,后续有遇到再更新。
将每层model填充到layers中
将每层输出的channel数写到ch数组中
concat与Detect层
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in {Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn}:
args.append([ch[x] for x in f])代码层面可以看到Concat是将f中的几个层的通道维度相加,并非单纯add
Detect模块将from中的数组append到args中
发表回复