
在自注意力机制中,键(key)和值(value)通常是通过将原始输入(如图像、文本等)通过线性变换得到的。
通常情况下,通过对特征向量进行线性变换(如全连接层)或卷积操作,可以得到三组不同的特征向量,分别用于查询、键和值。
换句话说,对于每个像素(或单词等),会有三个不同的特征向量:一个用作查询,一个用作键,一个用作值。这些特征向量是通过对原始输入进行特征提取和线性变换得到的,以便在自注意力机制中使用。
Q&A
qkv感性认识
Q:也就是一张图像经过卷积或全连接,由原本的hxwx3变成了 hxwx3,结果中的3层特征包含了1层q1层k一层v,是这样吗?
A:是的,您理解得很正确。
对于一张输入图像,经过卷积或全连接层后,会得到一个hxwx3的特征张量,其中的3表示通道数,即特征图的深度。在自注意力机制中,这个特征张量被视为三组特征:查询(query)、键(key)和值(value)。
因此,这个hxwx3的特征张量中的每个像素位置都包含了三个不同的特征向量,分别用于查询、键和值。在自注意力机制中,这些特征向量会被用来计算注意力权重,并生成最终的输出。
qkv学习特性
Q:我想知道的是这些特征提取与线性变换中的weight会被学习到吗?它可以反向传播吗?并且权重对值向量进行加权求和这个操作我不太理解,理论上每个pix对其他pix都有一个softmax(q * k)的权重系数,这个系数是如何与v进行加权的
A:是的,这些特征提取和线性变换中的权重通常是可以被学习的,并且可以通过反向传播来更新。在训练过程中,这些权重会根据损失函数来调整,以最小化损失并提高模型的性能。
qkv交互方式
关于权重对值向量进行加权求和的操作,可以简单地描述如下:
- 首先,对于每个查询向量 q_i,都会与所有键向量 k_j 进行内积运算,得到注意力权重系数 a_ij,其中 i 表示查询的位置,j 表示键的位置。
- 然后,将注意力权重系数 a_ij 与值向量 v_j 进行加权求和,得到查询位置 i 的输出特征表示 z_i。
数学上,查询位置 i 的输出特征表示可以表示为:
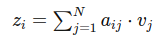
其中,N 表示输入序列的长度,a_ij 表示查询位置 i 对键位置 j 的注意力权重系数,v_j 表示值向量在位置 j 的值。这个操作就是加权求和,用来将值向量根据注意力权重进行加权,得到最终的输出表示。
在自注意力机制中,每个查询位置 i 的输出特征表示都是根据其与其他位置的注意力权重和值向量进行加权求和得到的,这样就能够充分利用每个位置与其他位置的关联性信息,从而生成最终的输出表示。
发表回复